
Database Replication & Sharding Explained
Learn how to handle massive datasets and high traffic loads with database replication and sharding.


When designing large-scale systems, one of the biggest challenges is ensuring the system remains responsive even when handling massive volumes of data and concurrent user requests. In such scenarios, the database often is the primary bottleneck.

And to make sure our systems remain fast and reliable even under heavy load, we can leverage two key techniques, which are called database replication and sharding.

Database Replication
Let’s start with replication. At its core, database replication involves creating multiple copies (replicas) of a database and distributing them across different servers.

This ensures high availability because it provides a safety net against database failures. If one database goes down, the application can switch to another replica, and this makes sure that they will get uninterrupted service and high availability.

It also scales the read capacity of our database because we now have multiple databases that can serve the data to our servers.

How Replication Works
Now, let’s explore the process of replication. There are two common methods of replication:
Leader-Follower (Master-Slave) Replication: In this setup, one database serves as the leader (master), and others act as followers (slaves). Write operations are directed to the leader, which then propagates the changes to the followers. Read operations can be distributed across both the leader and followers, which will enhance the read scalability.
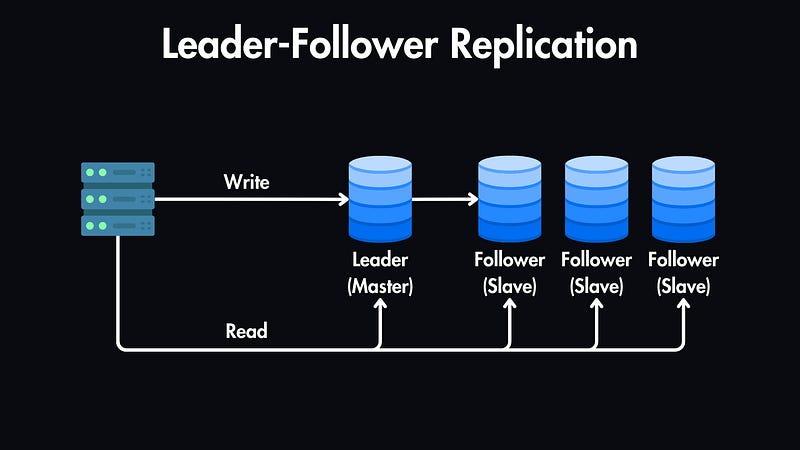
Leader-Leader Replication: Here, multiple databases act as leaders, and each of them can accept write operations. In this case, conflict resolution mechanisms are important to ensure data consistency.
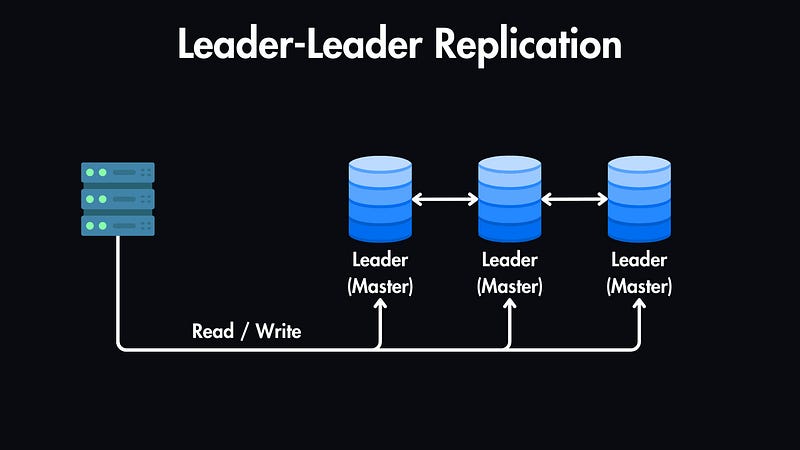
Async vs. Sync Replication
These database replications can be either synchronous or asynchronous.
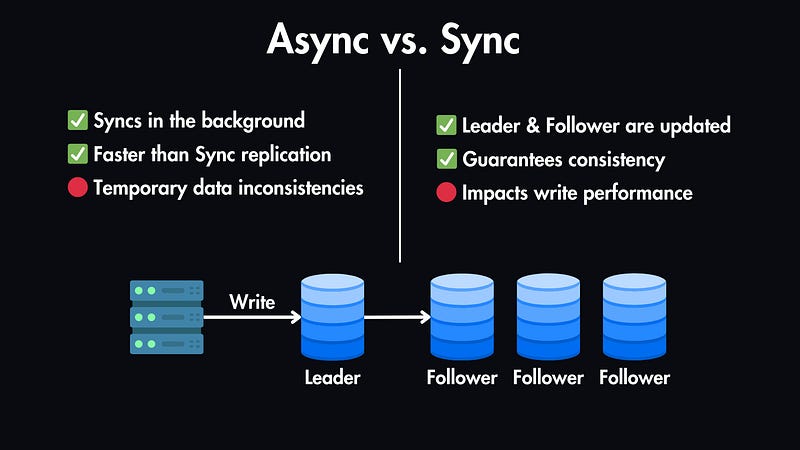
Asynchronous Replication: In this case, changes are propagated to replicas in the background. It's faster than synchronous replication but carries the risk of temporary data inconsistencies.
Synchronous Replication: Here, changes are committed to both the leader and replicas simultaneously, guaranteeing consistency but potentially impacting write performance.
Scaling Writes with Leader-Leader Replication
While the primary benefit of replication lies in scaling reads, Leader-Leader replication offers the possibility of scaling writes as well. However, it comes with the complexity of managing conflicts that may arise when multiple leaders accept write operations.
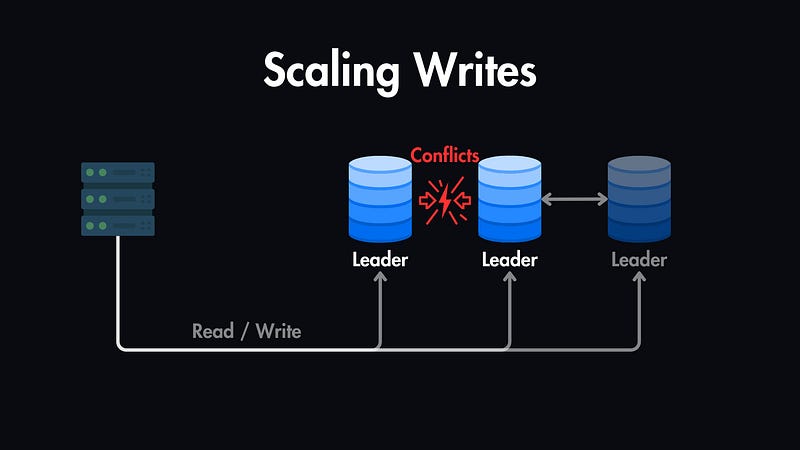
To maintain data consistency, there are multiple conflict resolution mechanisms which we can use:
Timestamp-based resolution: The update with the latest timestamp wins.
Last-write-wins: The most recent write, regardless of timestamp, overrides previous ones.
Custom conflict resolution logic: Application-specific rules can be applied to resolve conflicts based on the nature of the data and the desired behavior.

Sharding Databases
Now let's explore database sharding and its differences from replication.
The Problem Sharding Solves
When a database grows massive, even replication might not be enough. A single server might struggle to handle the storage and processing demands. Sharding tackles this by distributing the data across multiple servers, allowing horizontal scaling.

How Data is Split: Tables and Sharding
Typically, tables are sharded based on specific criteria. For instance, in an e-commerce platform, customer data might be sharded based on geographical location.

If you imagine a customers table that holds all customer information, we can arrange them by IDs. This means the first 1,000 users will be in the first shard, while the next 1,000 will be in the second shard, and so forth.
Deciding Where Data Goes: Shard Keys
But how do we determine where to place the data? For that, we use shard keys to determine how data is assigned to shards.
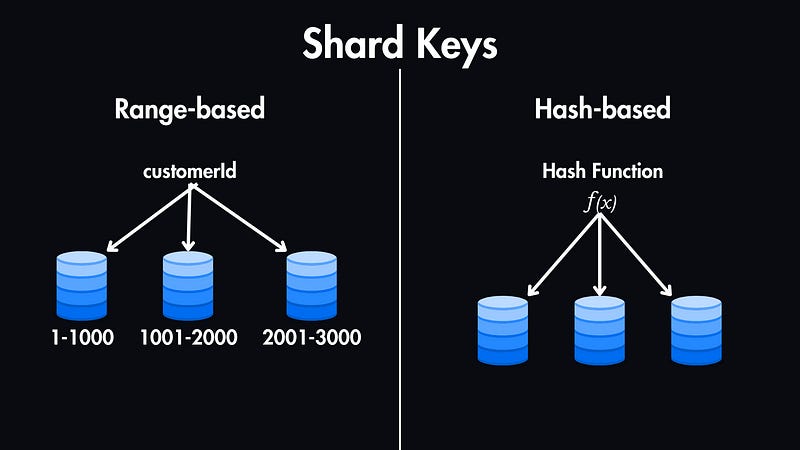
Range-based Sharding: In this case, data is partitioned based on ranges of the shard key. For example, customer IDs from 1 to 1000 might go to Shard 1, 1001 to 2000 to Shard 2, and so on.
Hash-based Sharding: For hash-based sharding, a hash function is applied to the shard key to determine the shard. This leads to a more even distribution of data but can make range queries less efficient.
For instance, in an e-commerce platform, customer data is sharded by country, so users from the same region are served by the same shard, which decreases latency. On the other hand, in a social media network, user posts and interactions are sharded according to user IDs for efficient access to data related to individual users.
Sharding in SQL vs. NoSQL Databases
Traditional SQL databases typically don't offer sharding out of the box. You need to implement the sharding logic yourself. On the other hand, many NoSQL databases like MongoDB have built-in sharding support, making it easier to scale horizontally.

Summary
So replication ensures high availability and scales read capacity, while sharding enables horizontal scaling by distributing data across multiple servers.
The choice between these techniques and implementation details depends on the system's requirements, and it’s also common to use both replication and sharding in combination.
If you’d like to learn more about database and system scaling techniques, be sure to check out our free developers' community.