
Database Scaling Basics Explained
Learn the basics of database scaling, including the differences between relational and non-relational databases and when to choose each type for your app.

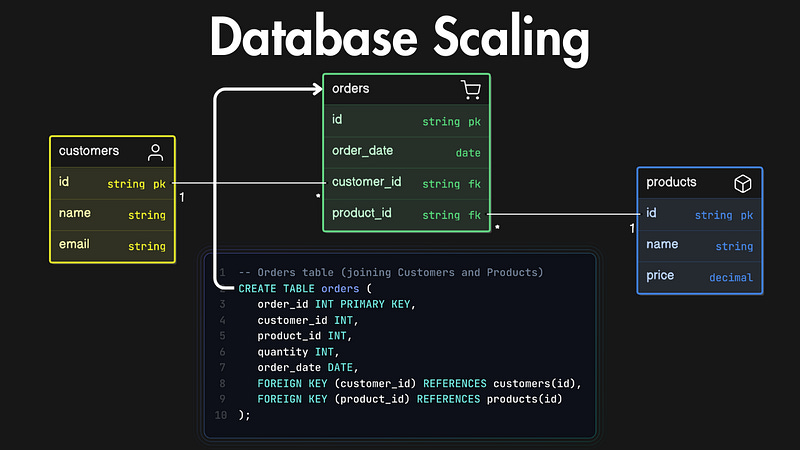
Database Scaling Basics
As our user base grows, a single server setup isn’t enough to handle the increased demand.
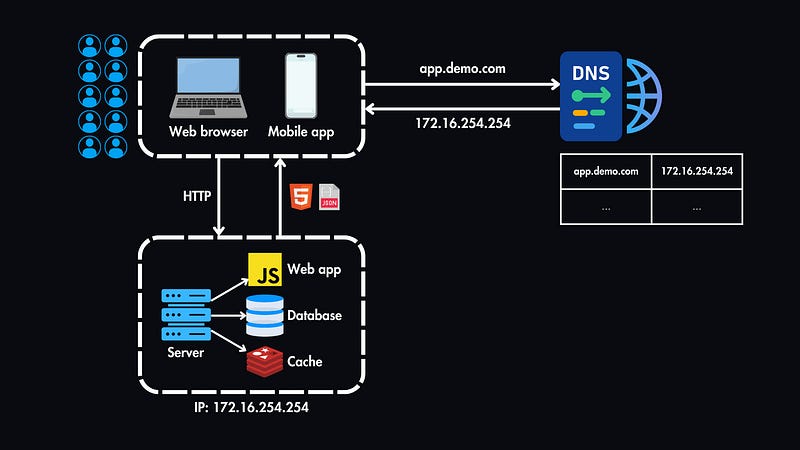
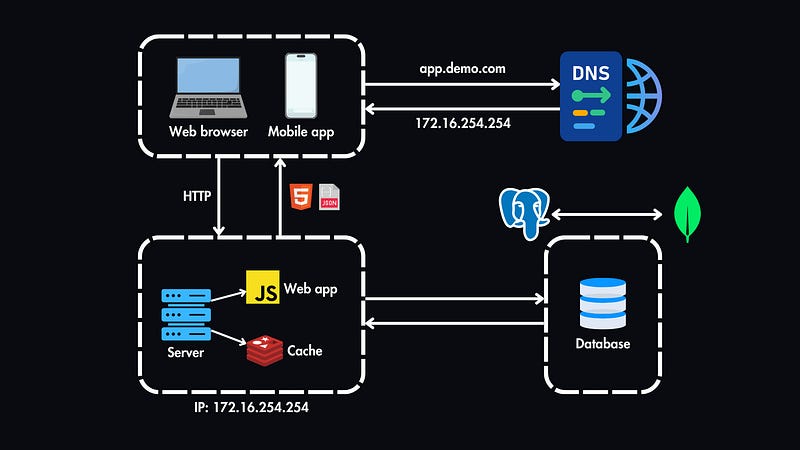
To accommodate more users, we can separate our web tier (handling web and mobile traffic) and data tier (managing the database).
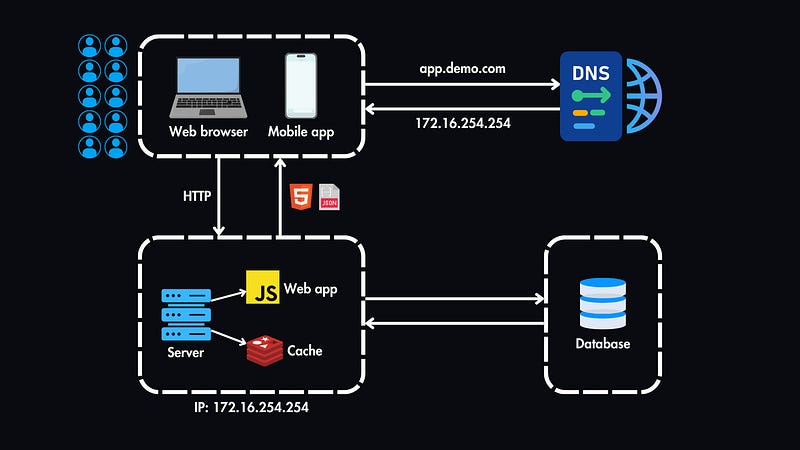
This setup enables us to scale each layer independently based on its specific demands.
Choosing the Right Type of Database
A crucial decision in scaling databases is selecting the type of database that best fits your application’s needs. This choice influences how data is stored, accessed, and scaled. Let’s break this down into two primary categories:
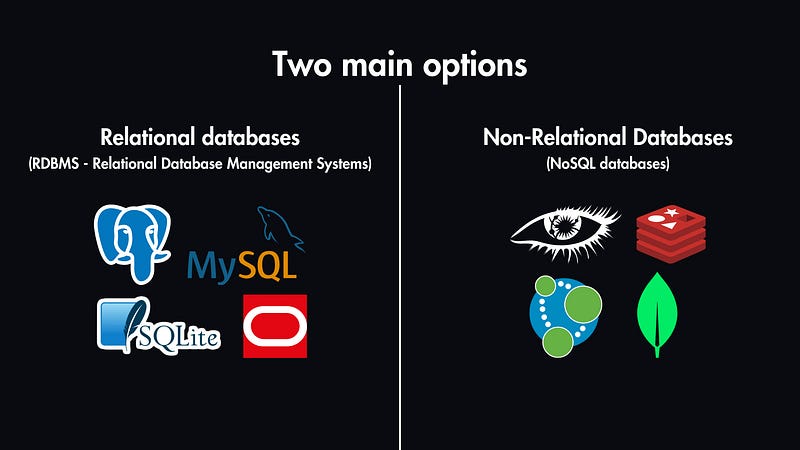
Relational Databases (RDBMS): These are structured and organized in tables with rows and columns. Some popular relational databases include MySQL, PostgreSQL, and Oracle Database.
Non-Relational Databases (NoSQL): Designed for flexibility and speed with large volumes of unstructured data, these databases include key-value stores (e.g., Redis), document stores (e.g., MongoDB), wide-column stores (e.g., Cassandra), and graph databases (e.g., Neo4j).
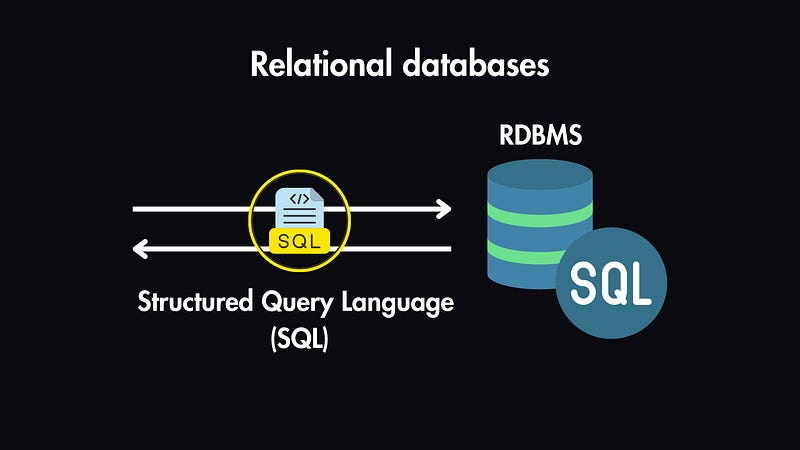
1. Relational Databases
Relational databases use Structured Query Language (SQL) for data management. They excel in scenarios where data relationships are critical.
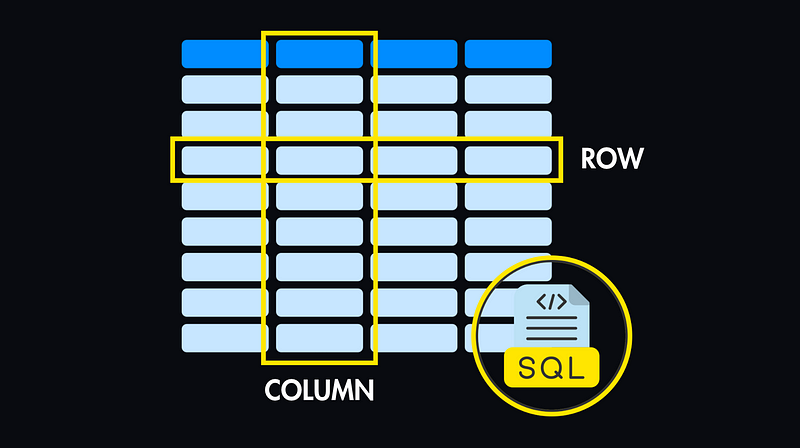
Structure: Data is stored in tables resembling spreadsheets. Each table represents a specific entity, like customers or orders, with defined columns (attributes) and rows (records).

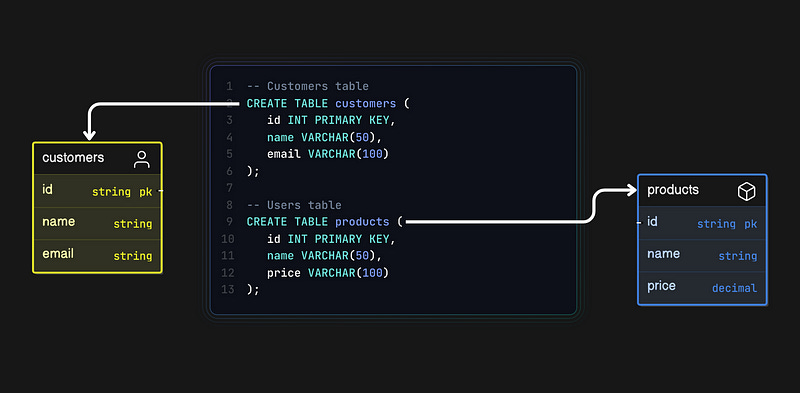
Example Use Case: An e-commerce application could use relational databases to store customer details and their respective orders in separate tables while enabling complex queries to link the data.
Advantages:
They support complex join operations across multiple tables, making them effective for applications with interrelated data.
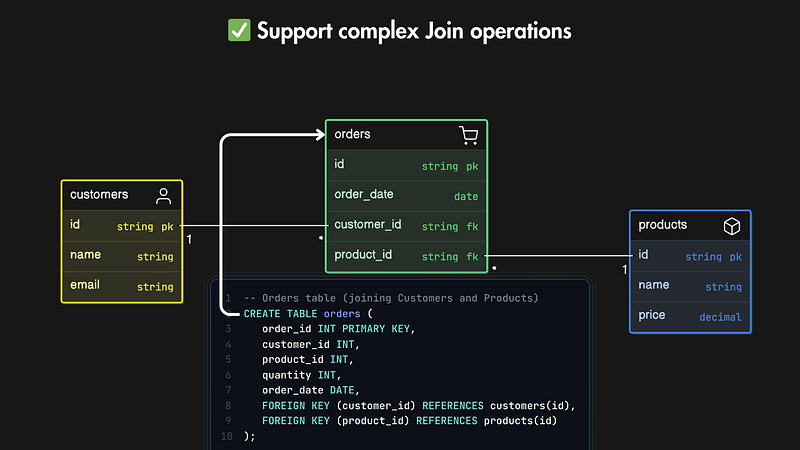
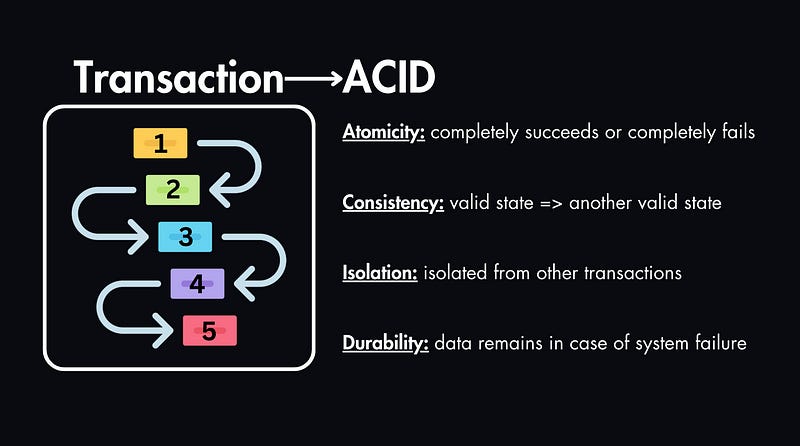
They provide robust data consistency and integrity, especially for transactions.
2. Non-Relational Databases
Non-relational databases, or NoSQL databases, prioritize scalability and flexibility. Unlike relational databases, they don’t rely on a fixed schema, making them well-suited for dynamic and unstructured data.

Here’s a breakdown of the most common types:
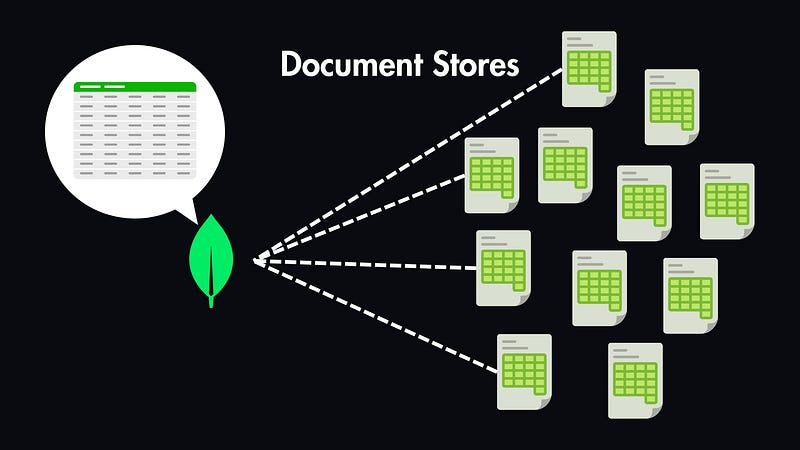
Document Stores (e.g., MongoDB)
Data is stored as JSON-like documents, allowing for complex data structures within a single record.
Example: Storing user profiles, where each document can have varying attributes without predefined columns.
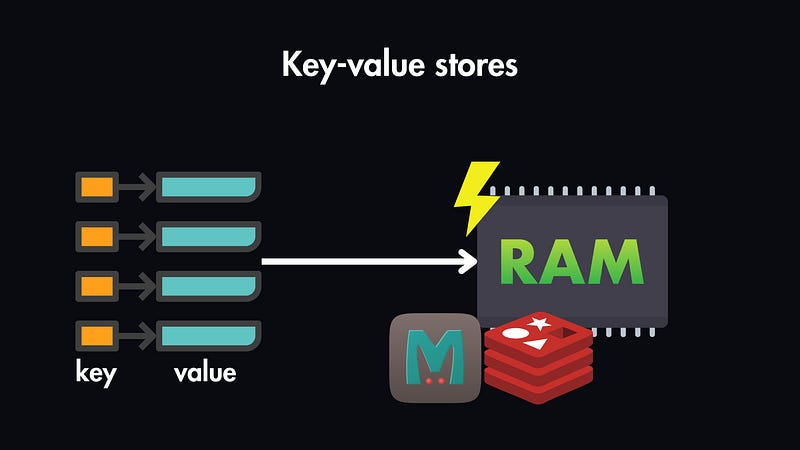
Key-Value Stores (e.g., Redis)
Data is stored as simple key-value pairs, making it ideal for caching and session storage.
Example: Storing user sessions, where the key is the session ID, and the value holds user-specific data.
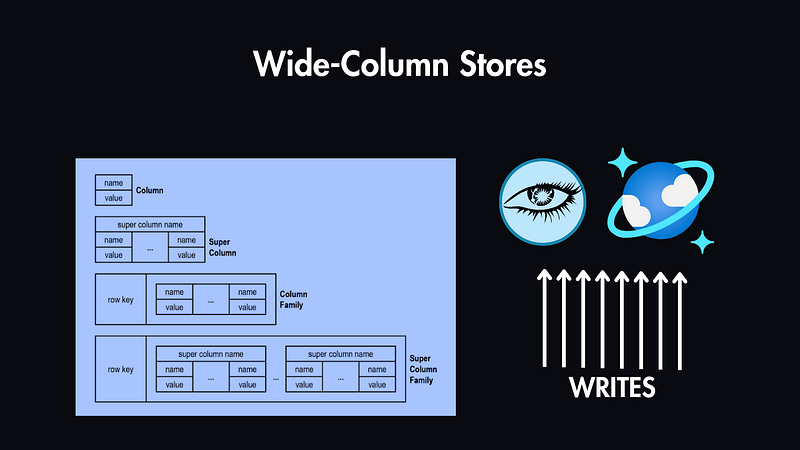
Wide-Column Stores (e.g., Cassandra)
Data is stored in tables, rows, and dynamic columns. Columns can be added on the fly, making it suitable for data with evolving schemas.
Example: A time-series application monitoring server performance in cloud infrastructure — tracking metrics like CPU usage or memory consumption over time.
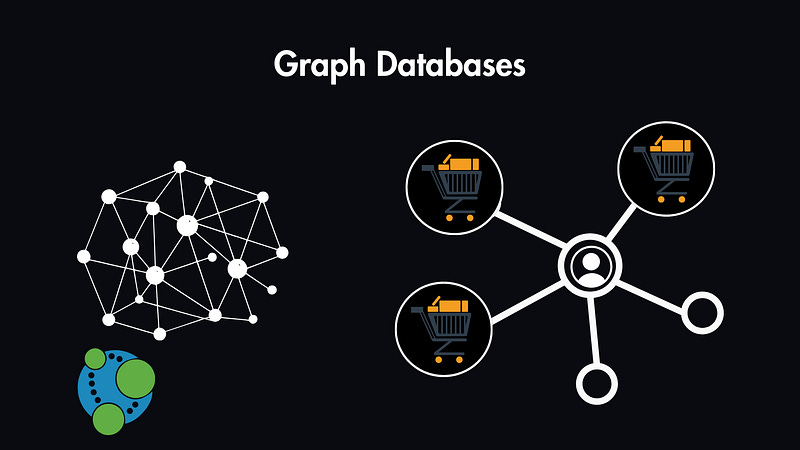
Graph Databases (e.g., Neo4j)
Focus on relationships, storing data as nodes (entities) and edges (relationships). Both nodes and edges can have properties, making them ideal for highly interconnected data.
Example: Managing an e-commerce platform’s order tracking, where nodes represent customers and orders, and edges represent relationships such as “placed by” or “contains products”.
Advantages of Non-Relational Databases:
Handle large, dynamic datasets without the rigid structure of relational databases.
Optimized for horizontal scalability and distributed storage, enabling low-latency responses even under heavy loads.

When to Use Relational vs. Non-Relational Databases
Your choice depends on the nature of your application and its requirements:
Use Relational Databases when:
Data is well-structured with clear relationships (e.g., tracking customers and orders).
Strong consistency and transactional integrity are critical (e.g., banking systems).
Use Non-Relational Databases when:
The application needs rapid responses and flexible schemas (e.g., social media feeds or recommendation engines).
The data is unstructured, semi-structured, or massive in volume.
Key Takeaways
Separate tiers allow you to scale your web server and database independently.
Relational databases are ideal for applications needing structured, interrelated data and strict consistency.
Non-relational databases are better for large, unstructured, or highly flexible data storage needs with fast access requirements.