


Load Balancers Explained in 7 Minutes
Learn about the top 7 load balancing algorithms and strategies.

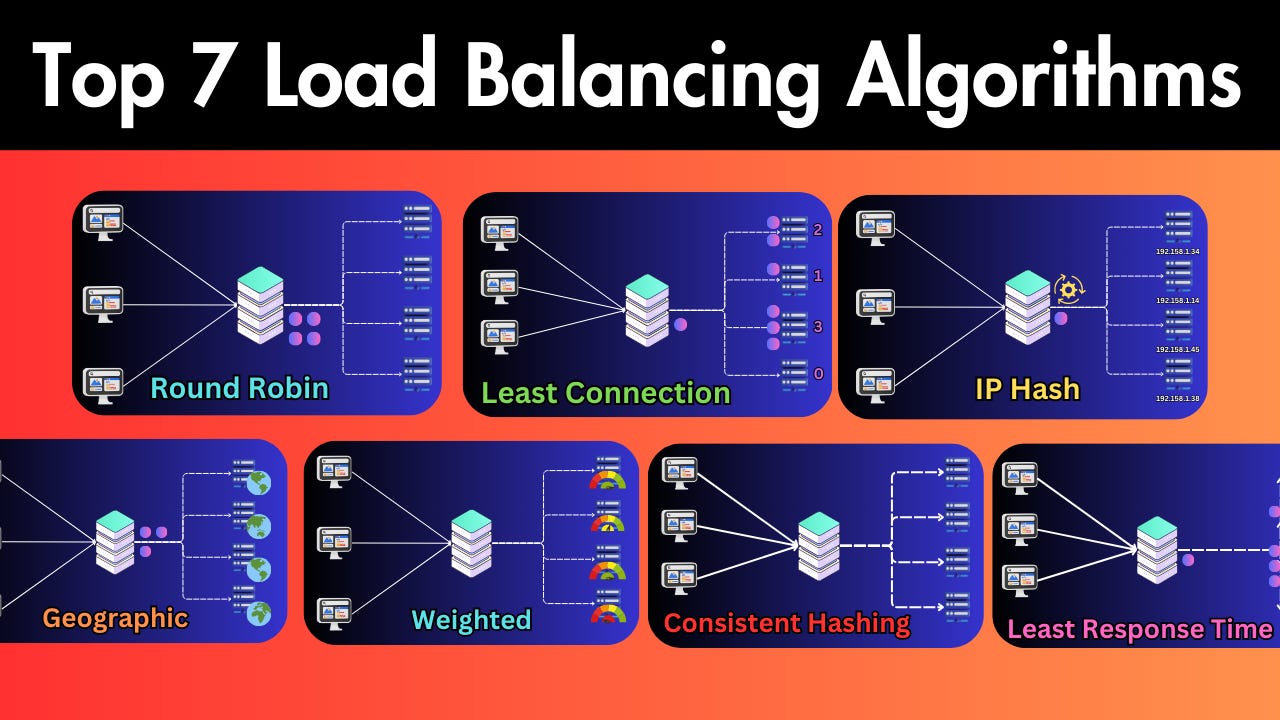
Load balancers are essential components in web infrastructure, distributing incoming traffic across multiple servers while ensuring no single server bears too much load.

But how does this distribution actually happen? Let’s explore seven common load-balancing strategies and algorithms to understand the logic behind traffic distribution.
1. Round Robin
Round Robin is one of the most popular algorithms due to its simplicity. In this approach, each server in the pool gets requests in a sequential, rotating order.
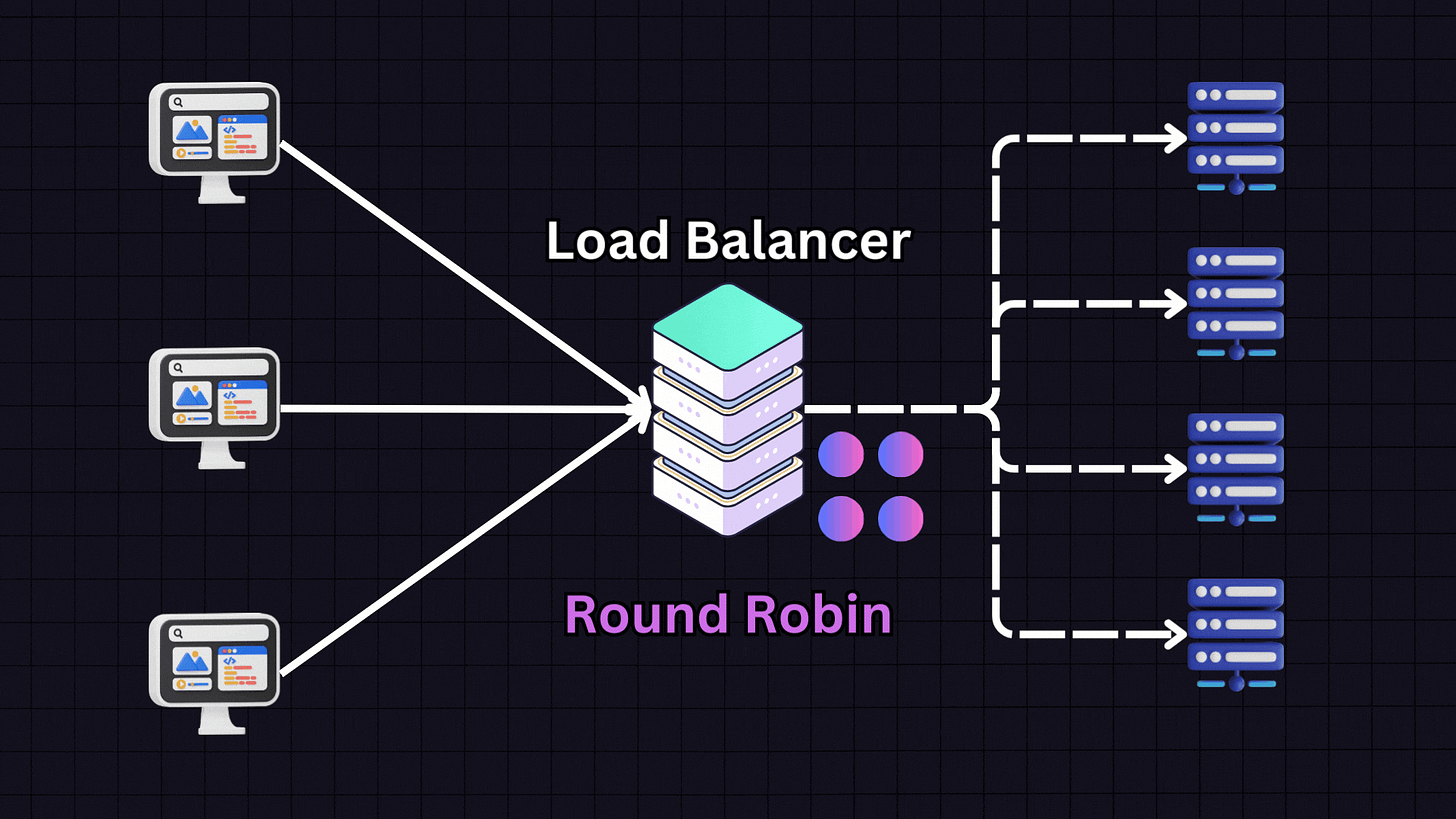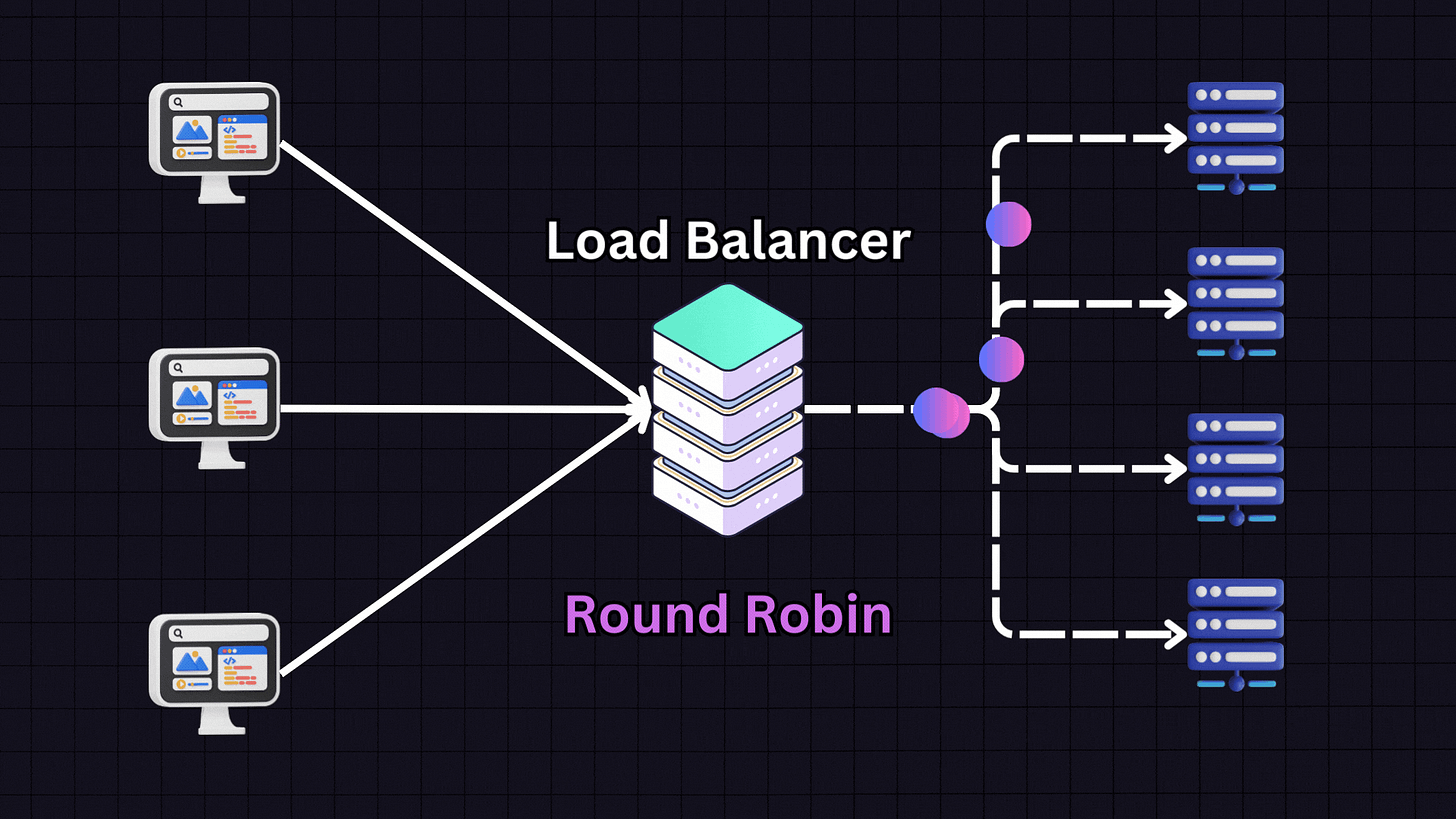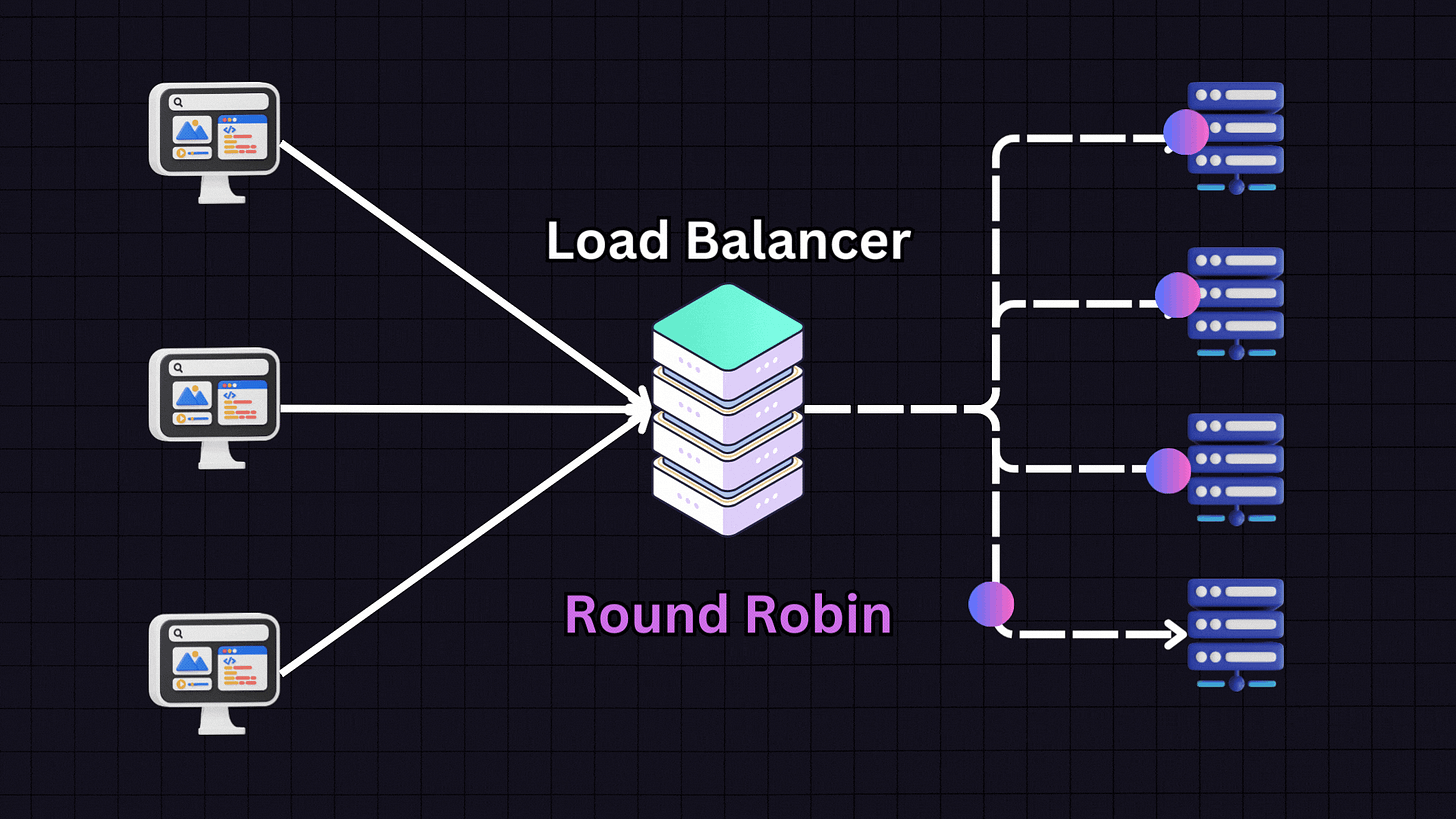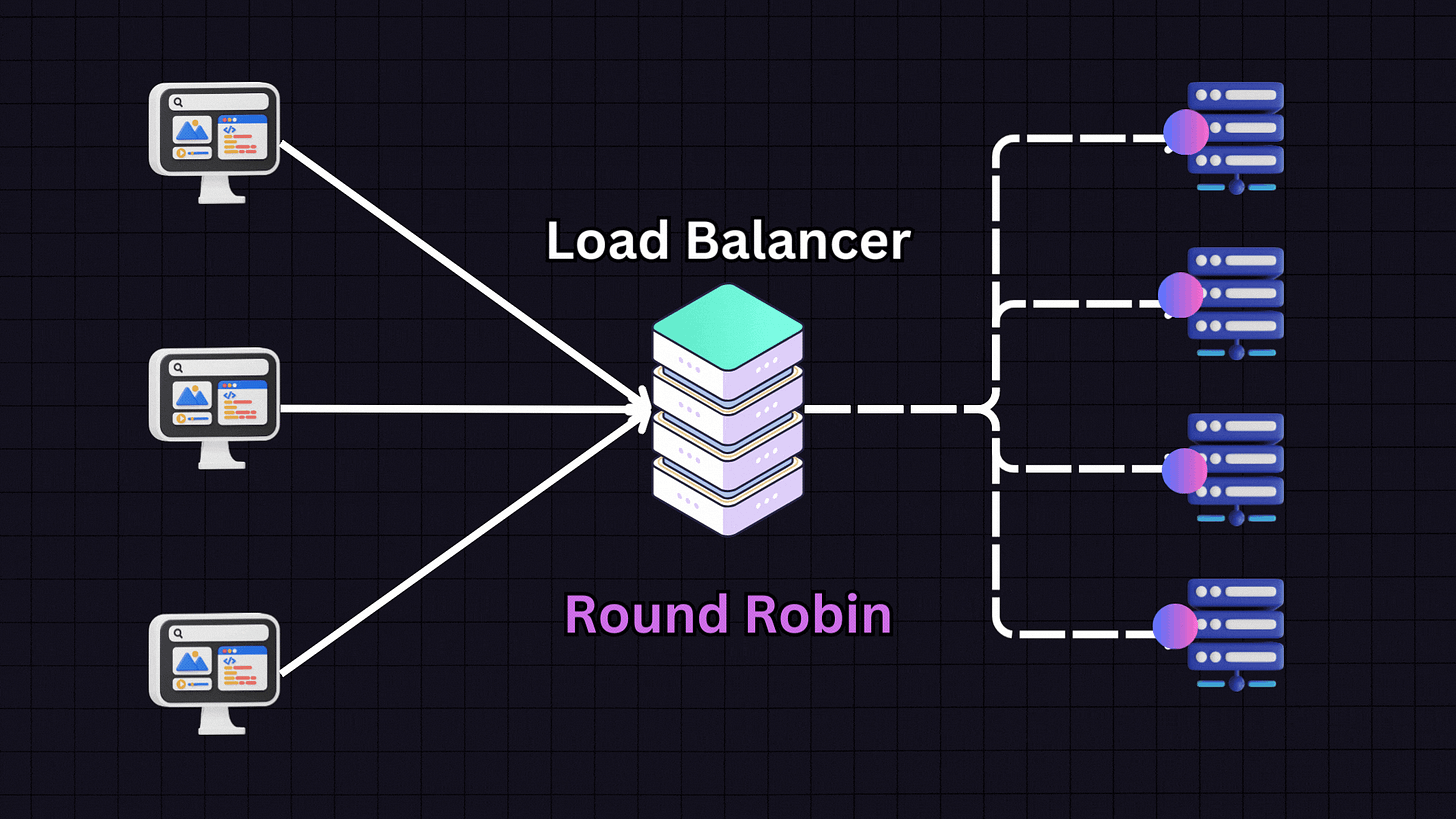
For example:
First request → Server 1
Second request → Server 2
Third request → Server 3
Fourth request → Server 4
Fifth request → Back to Server 1
This pattern continues in rotation. Round Robin works best when all servers have similar specifications and capabilities, as it assumes each server can handle an equal load.
2. Least Connections
The Least Connections algorithm directs traffic to the server with the fewest active connections.
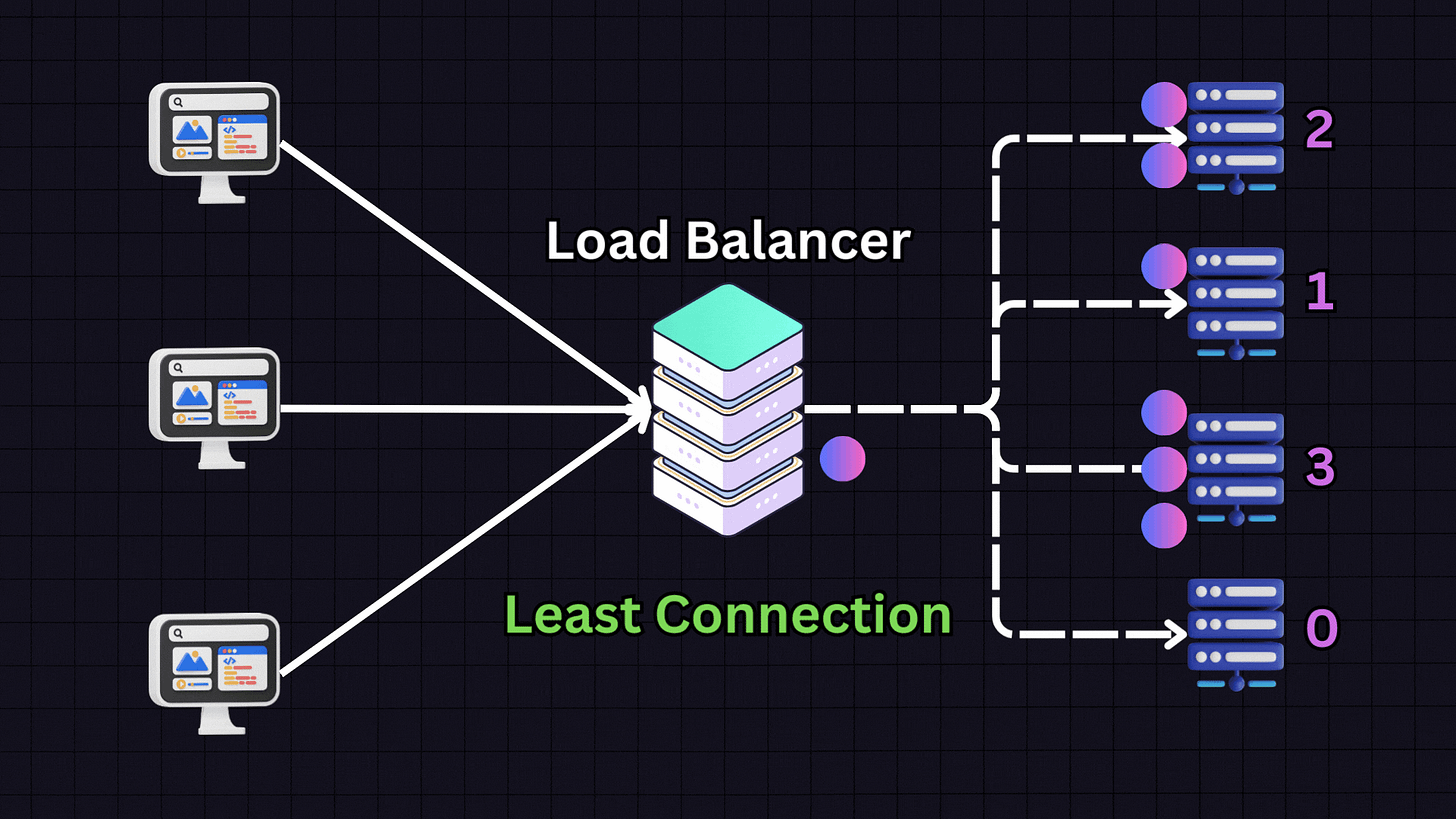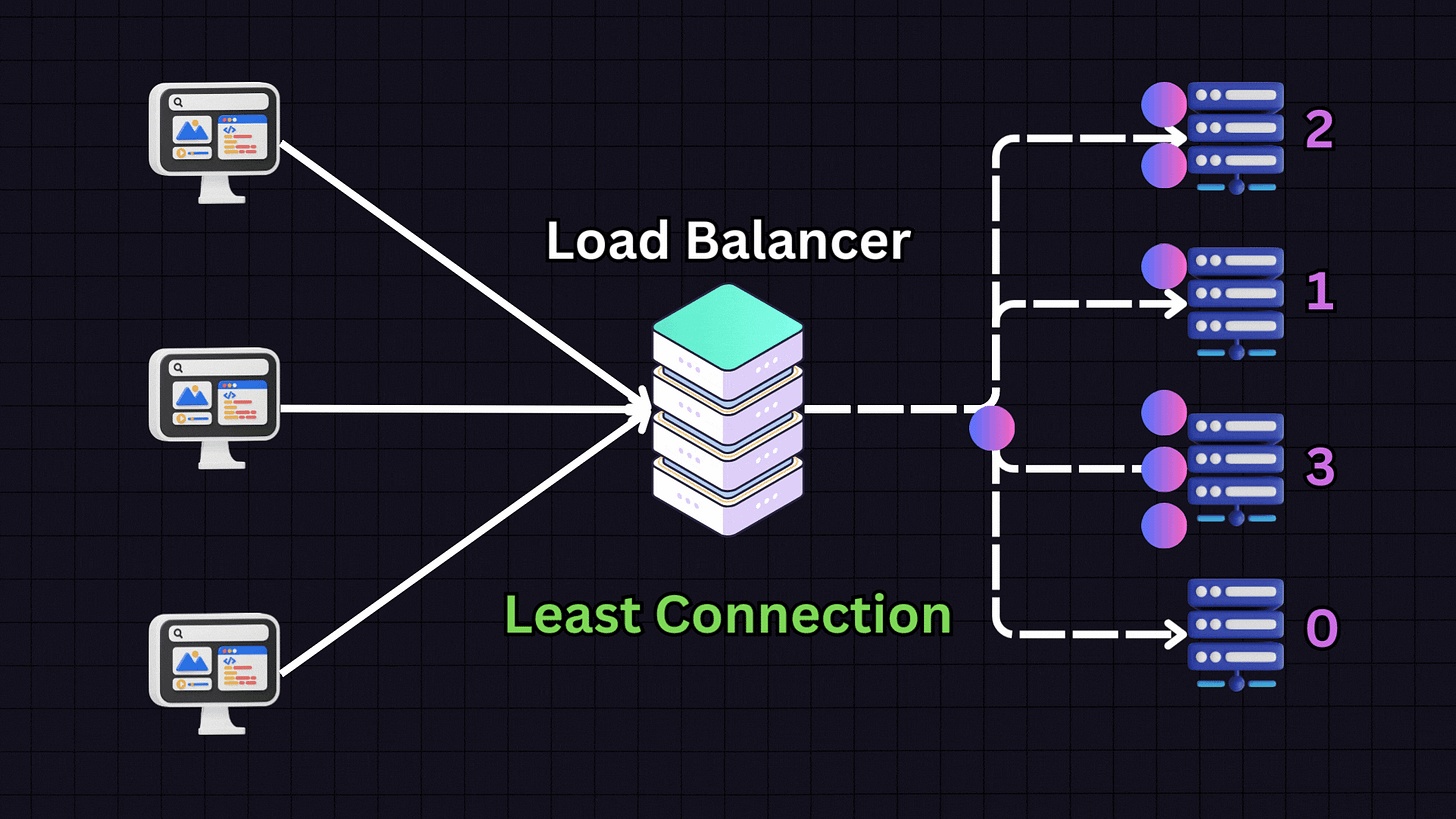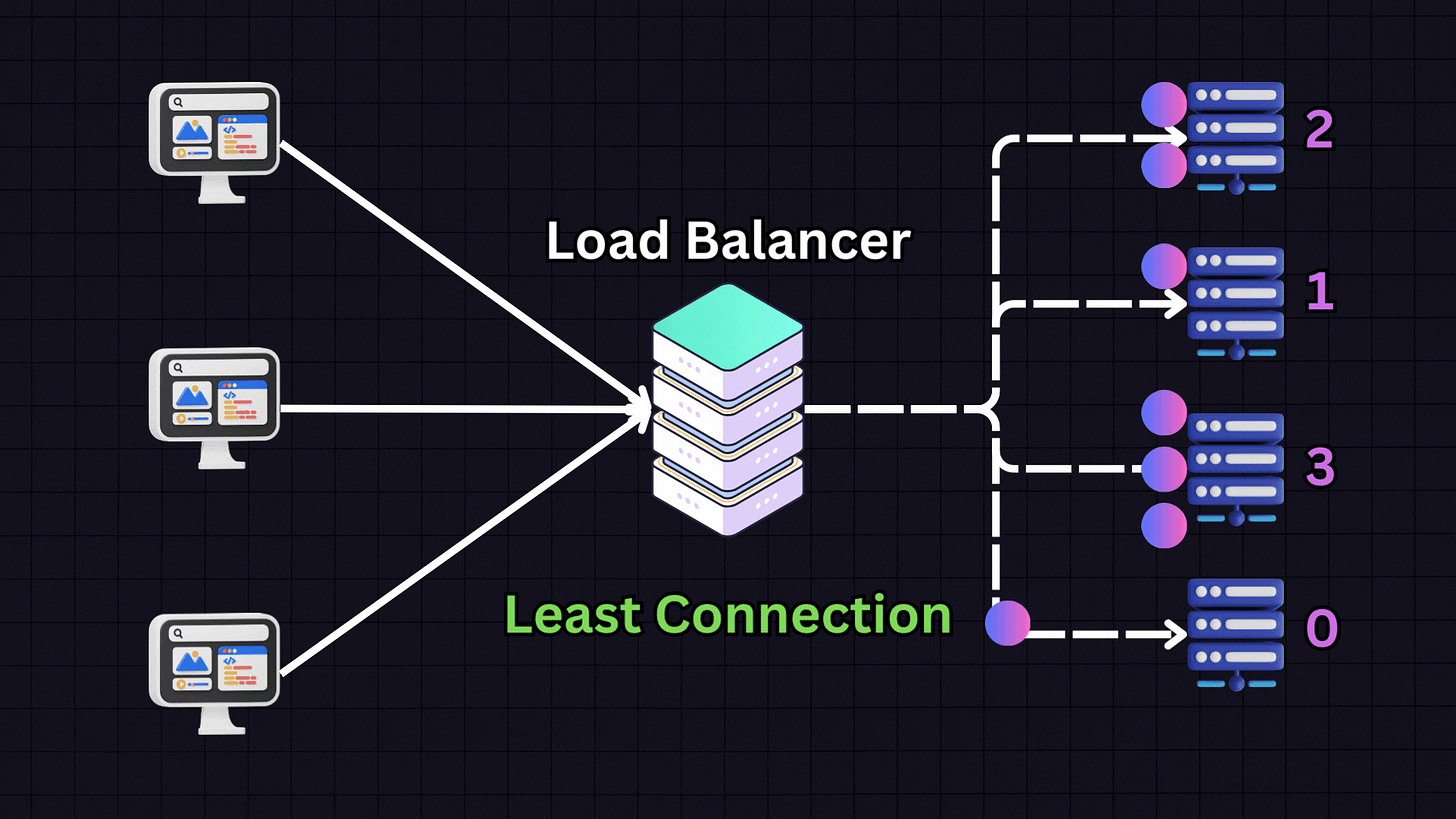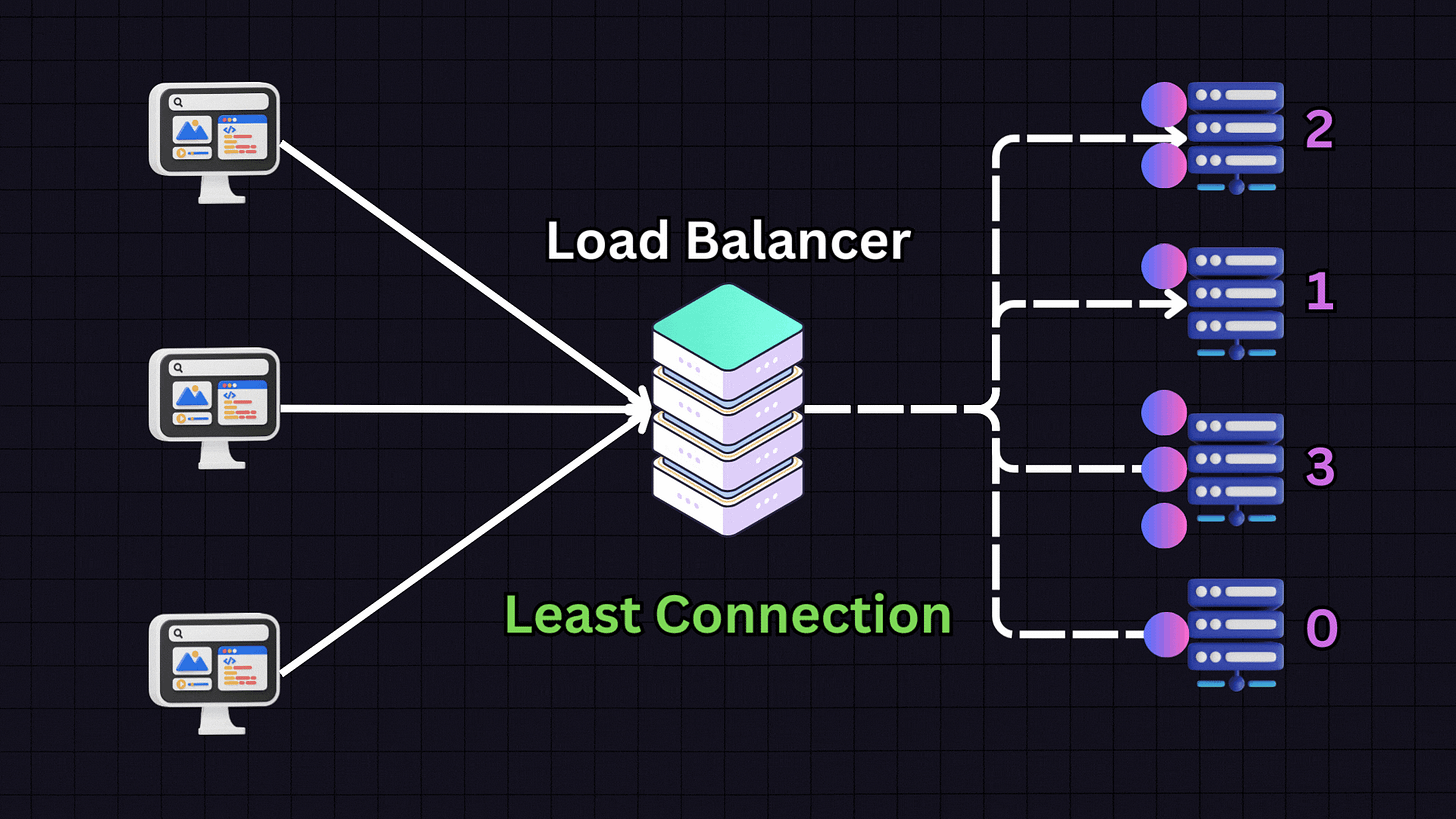
For instance, if we have:
Server 1: 10 active connections
Server 2: 9 active connections
Server 3: 30 active connections
Server 4: 10 active connections
When a new request arrives, the load balancer will direct it to Server 2 because it has the fewest active connections. This approach is particularly useful for applications with variable session lengths, where some connections might last longer than others.
3. Least Response Time
The Least Response Time algorithm focuses on the responsiveness of servers. It chooses the server with the lowest response time and fewest active connections.
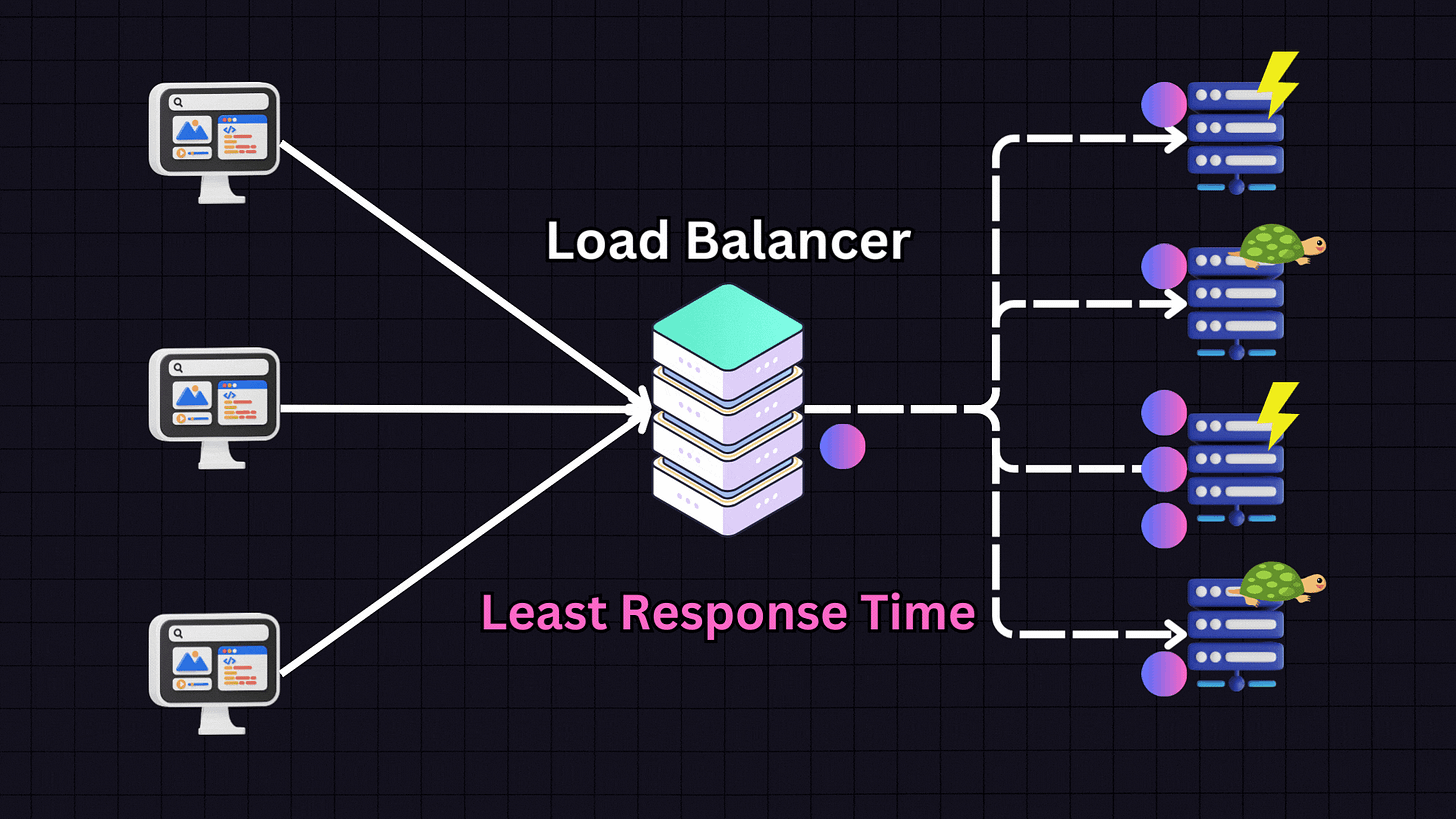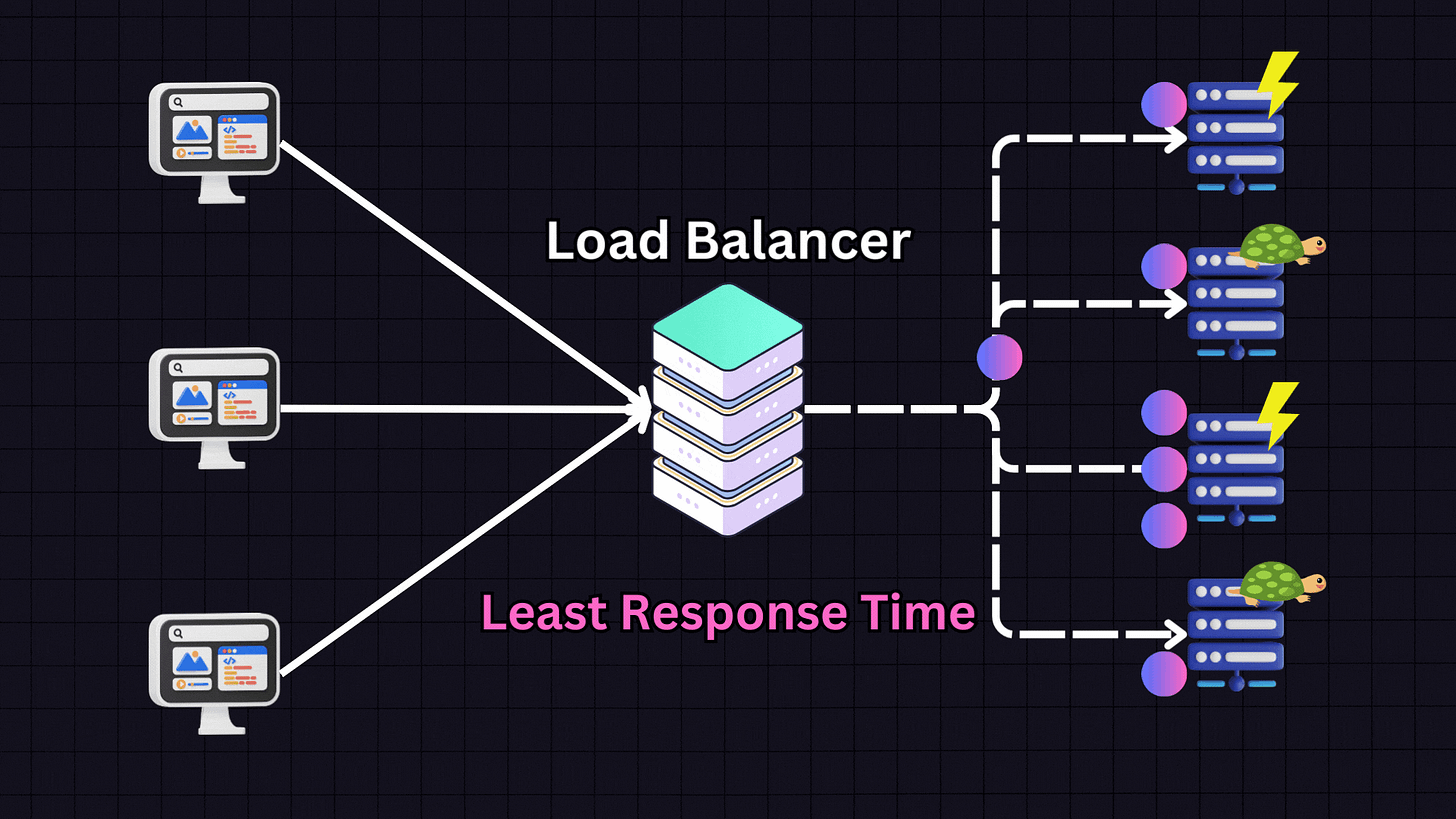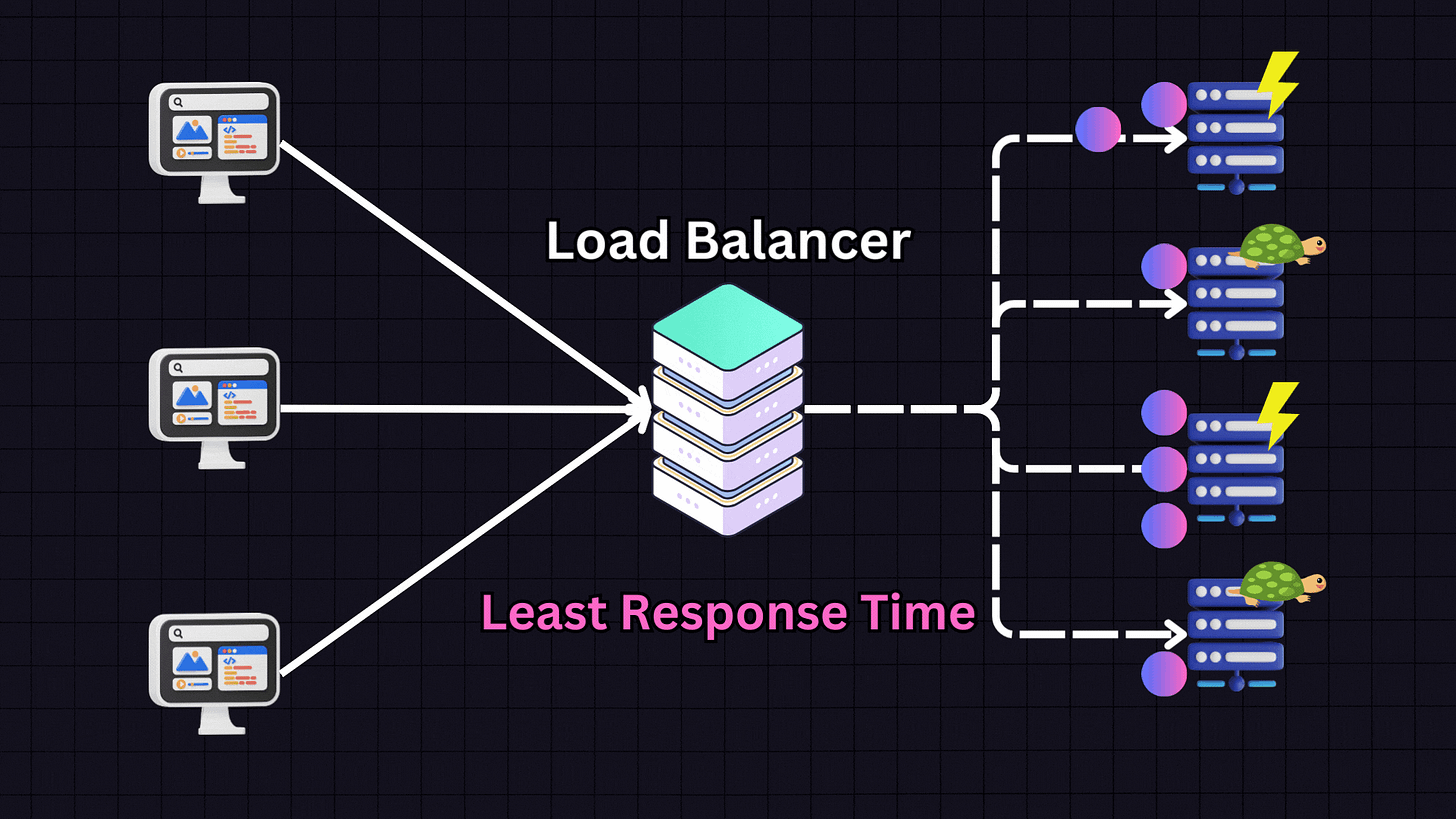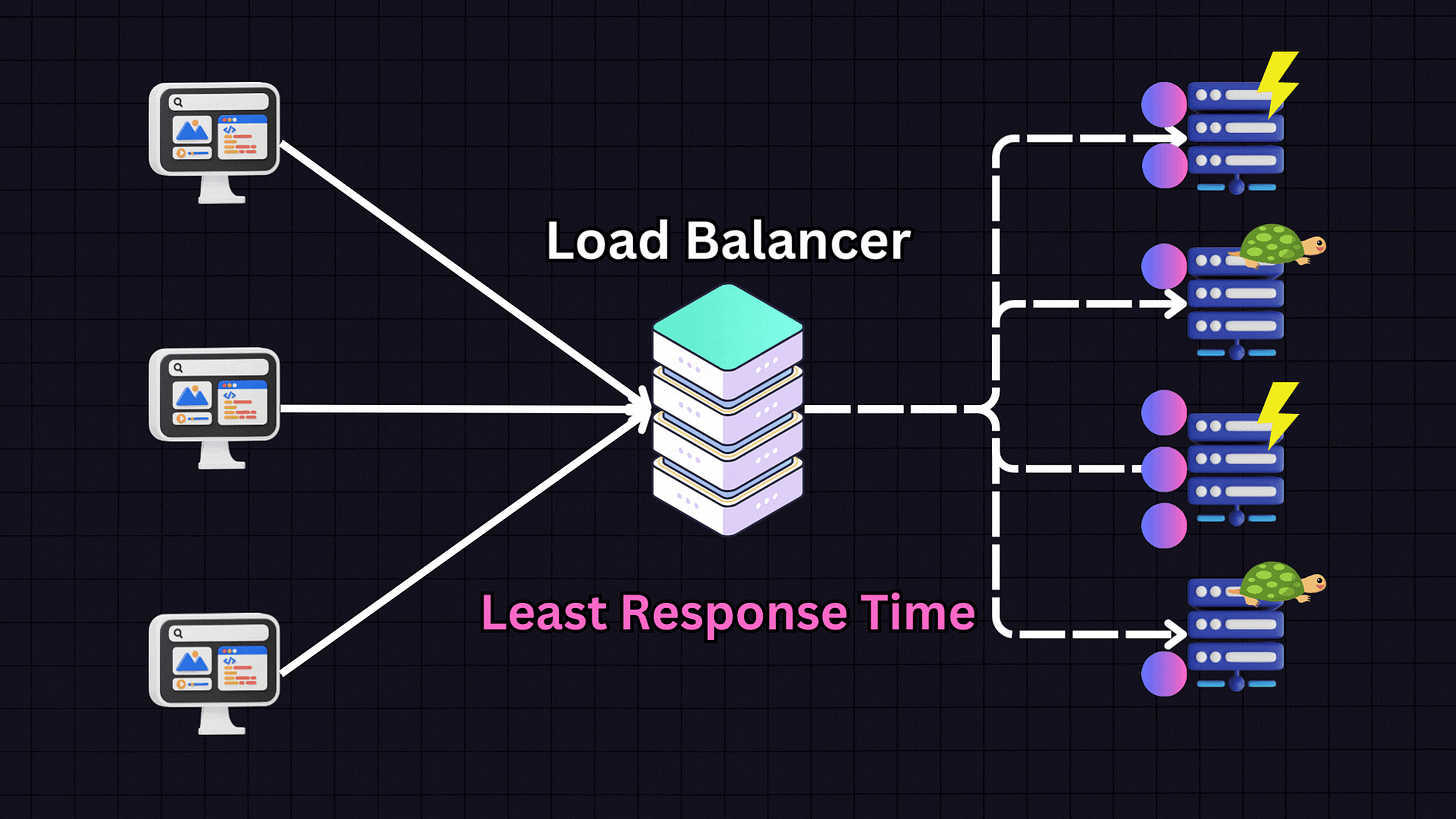
For example, if we have:
Server 1: High responsiveness
Server 2: Low responsiveness
Server 3: Medium responsiveness
Server 4: Low responsiveness
The load balancer will prioritize Server 1 due to its high responsiveness. However, it also considers active connections. If Server 1 reaches a high number of connections (e.g., 30), the load balancer might switch to Server 3 (medium responsiveness) and distribute some traffic there. This approach is effective when providing the fastest response time to users is the primary goal.
4. IP Hash
The IP Hash algorithm determines which server receives a request based on the hash of the client’s IP address.
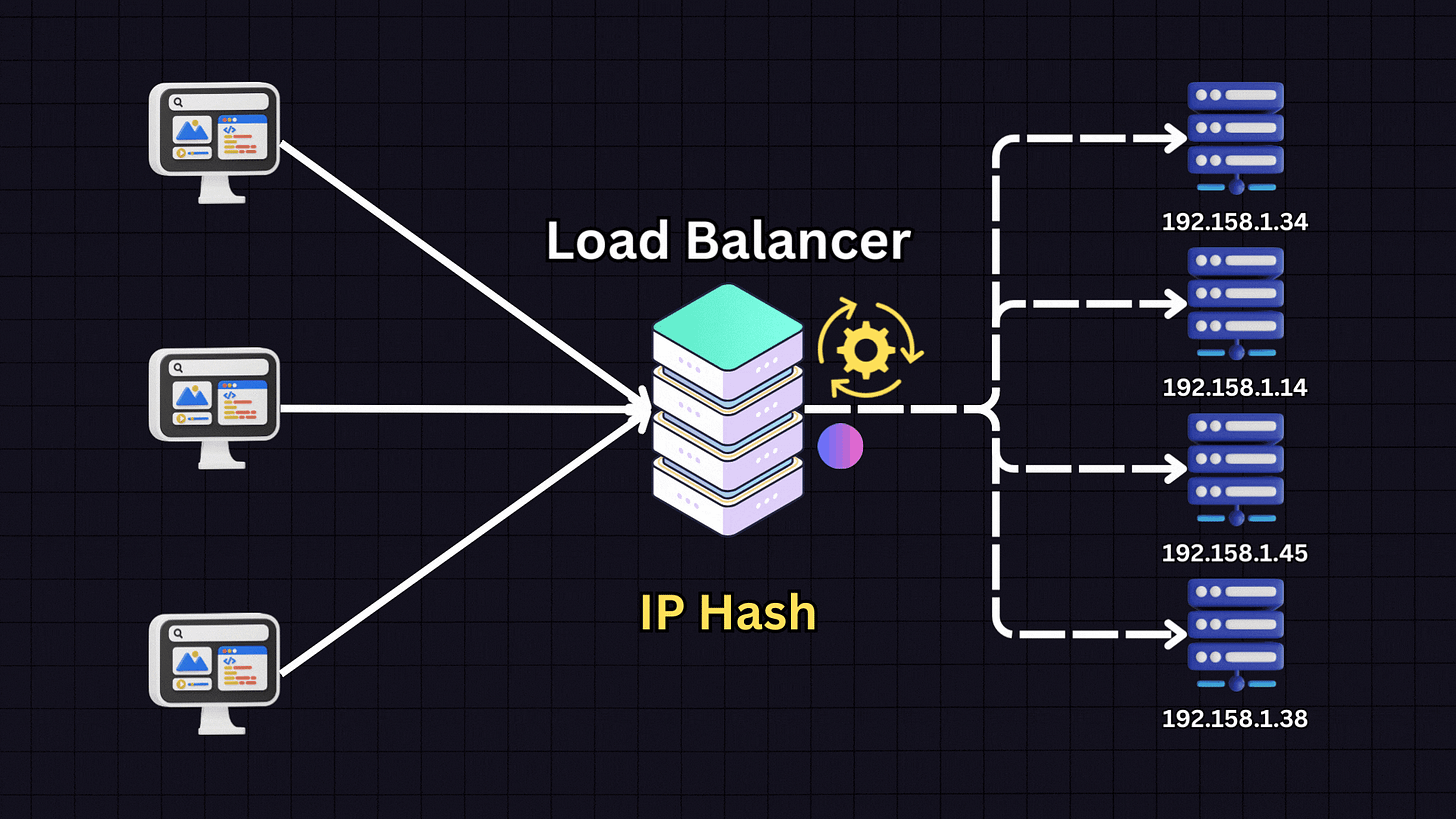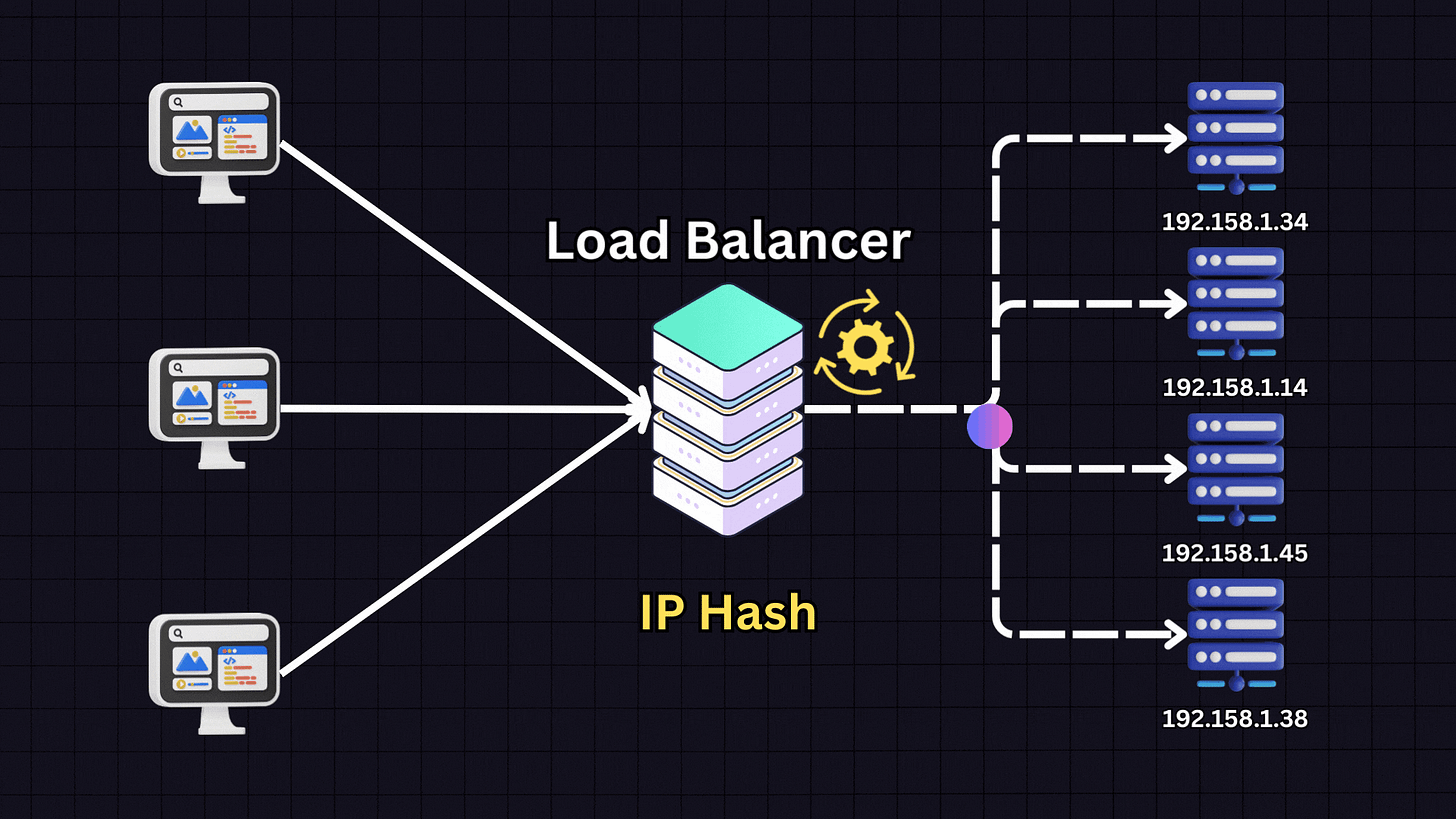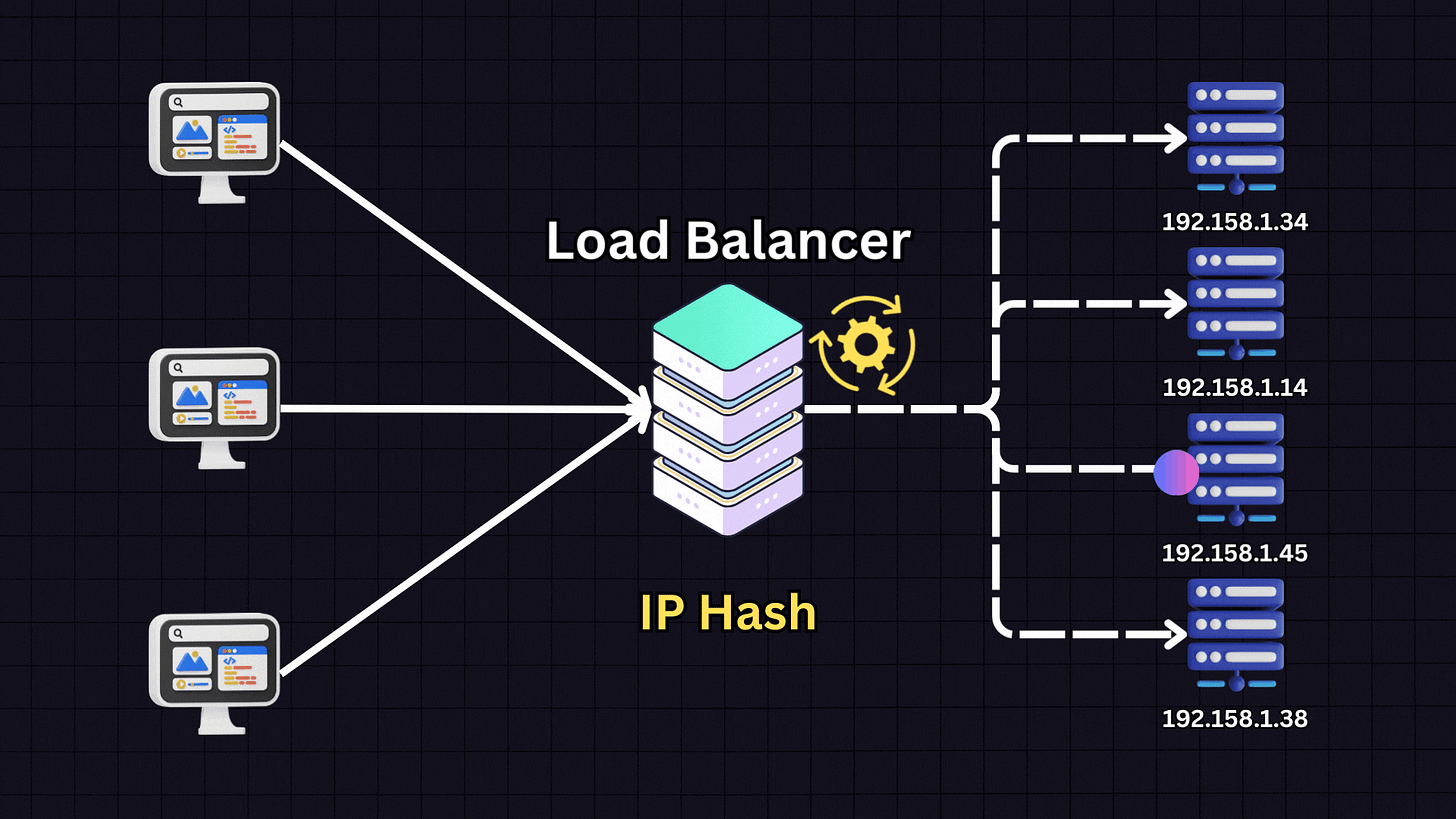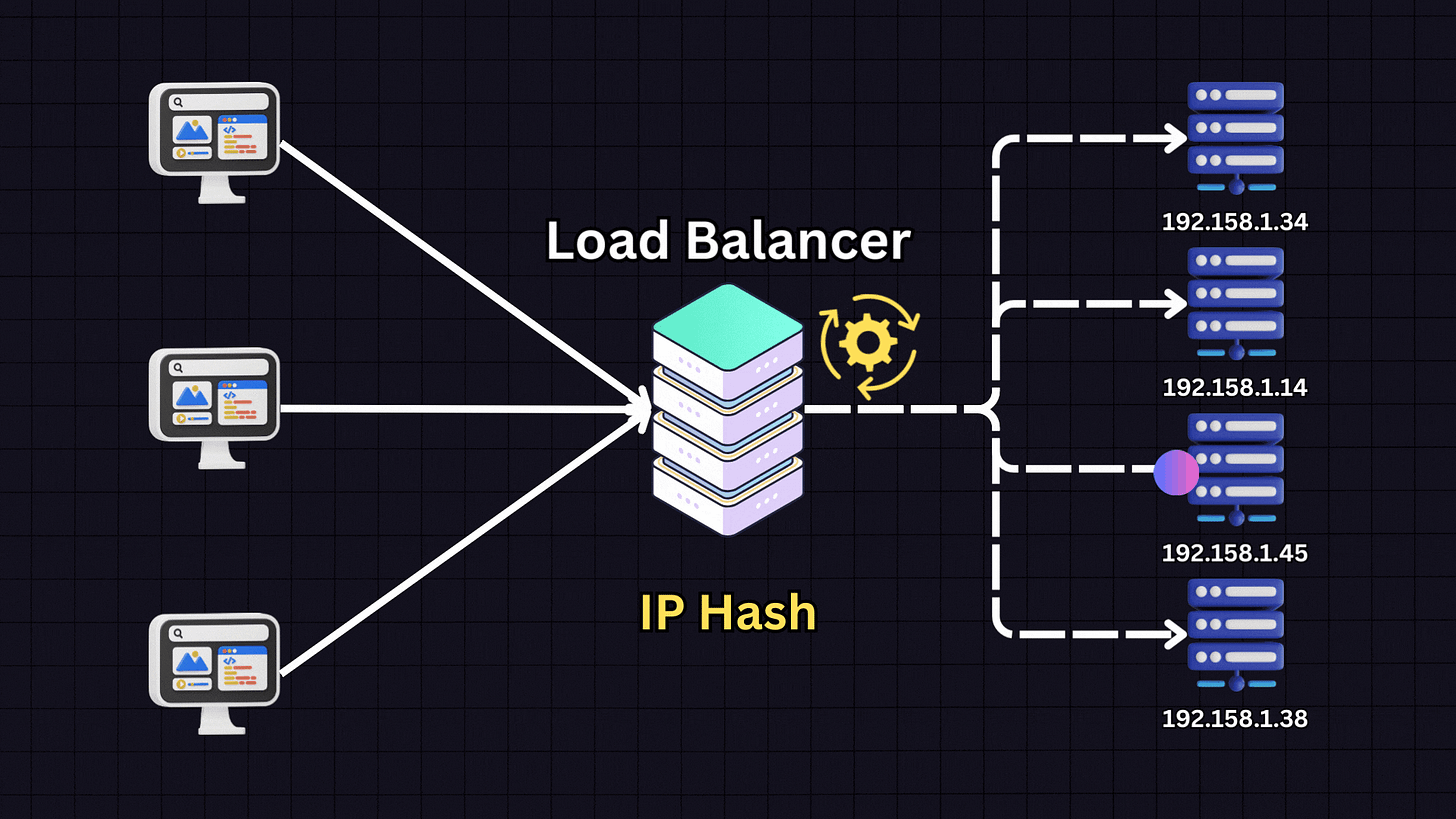
When a client makes a request, the load balancer:
Takes the client’s IP address
Applies a hash function to it
Based on the hash result, directs the client to a specific server
This ensures that a client consistently connects to the same server for all future requests. IP Hash is useful for applications where session persistence is important, such as when each server stores specific client information.
5. Weighted Algorithms
Weighted algorithms are variants of the above methods where servers are assigned weights based on their capacity and performance metrics.
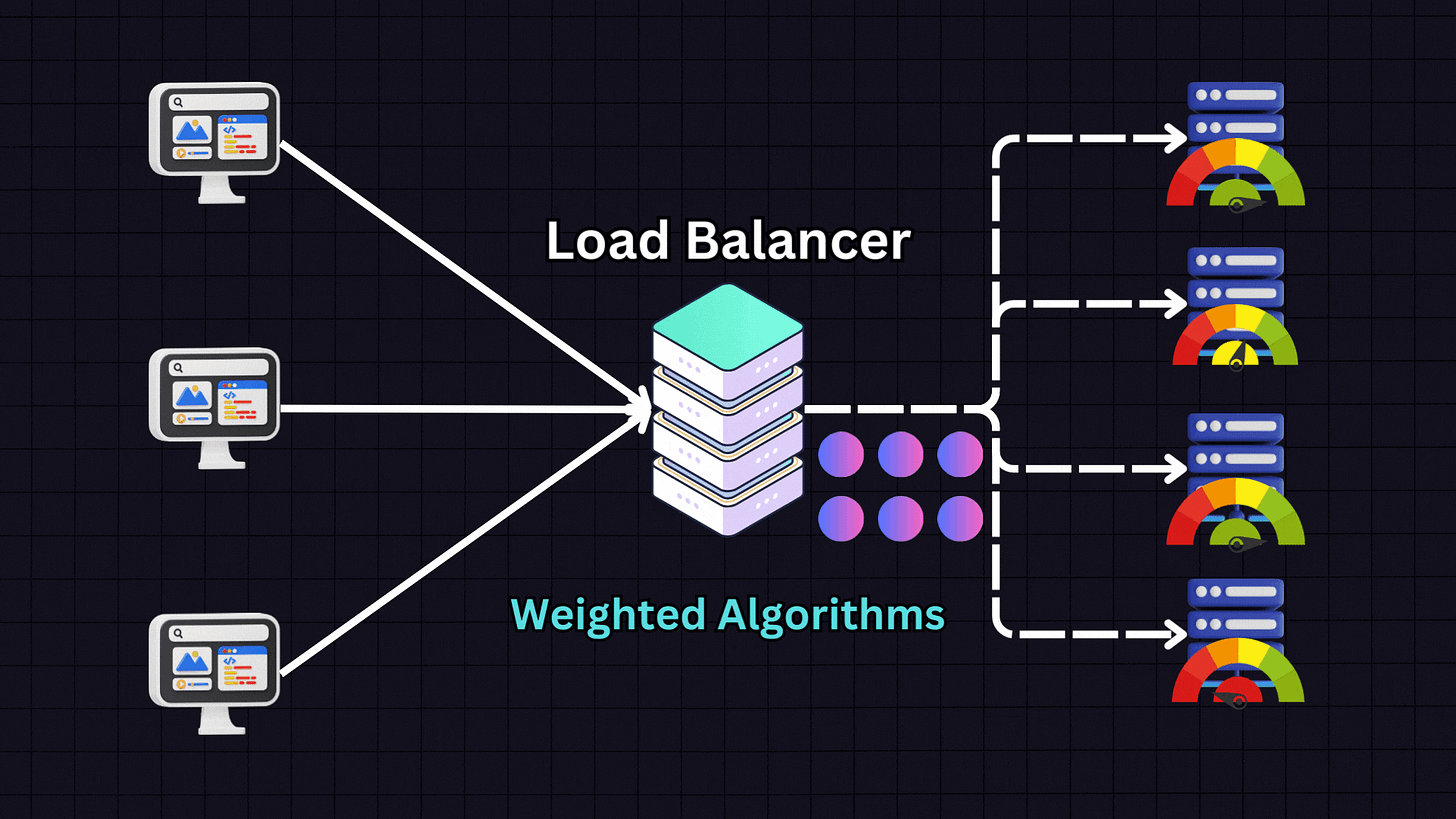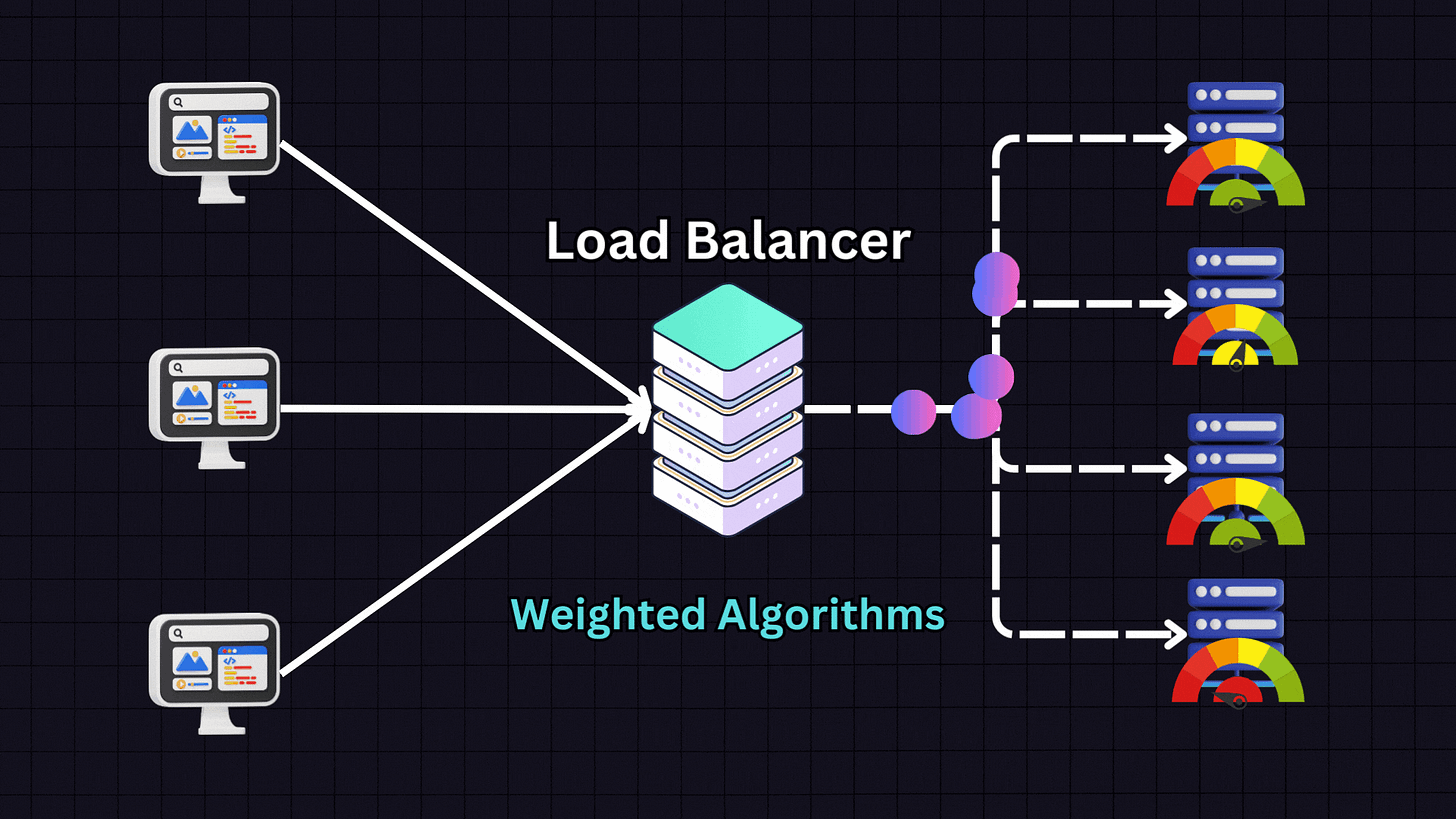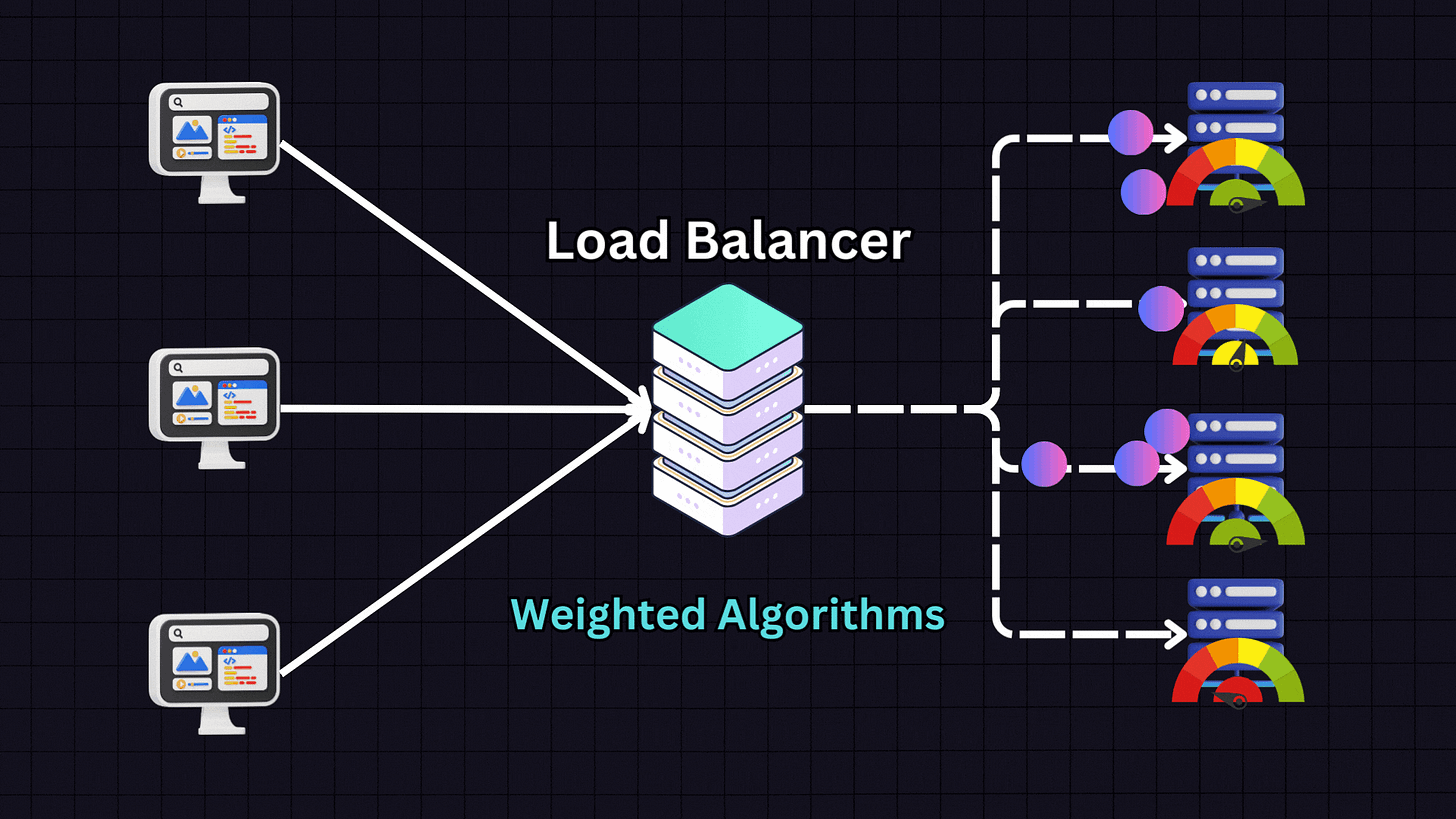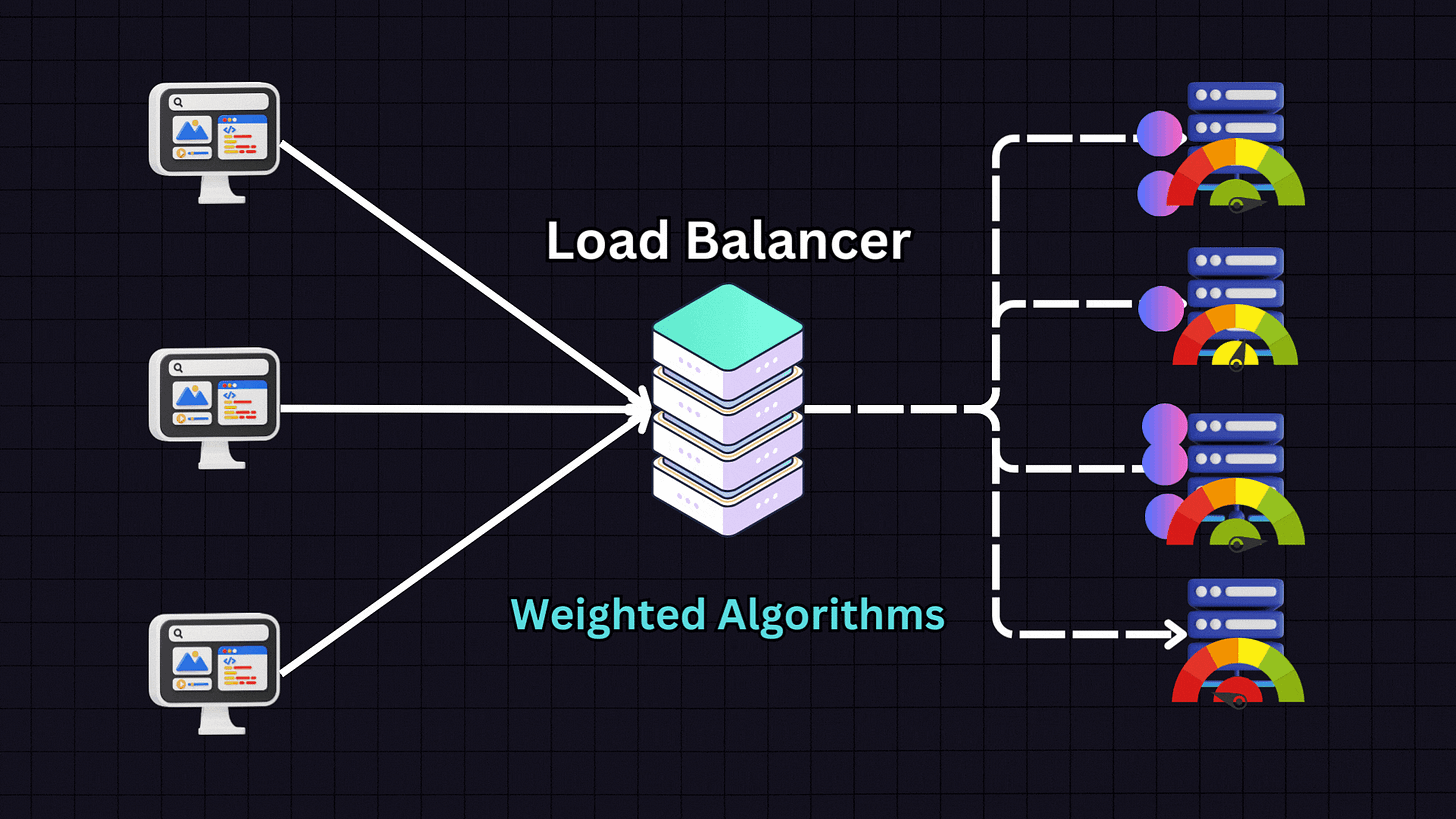
For example, if we have:
Server 1: 16GB RAM (weight: 1)
Server 2: 32GB RAM (weight: 2)
Server 3: 64GB RAM (weight: 4)
Server 4: 128GB RAM (weight: 8)
The load balancer will distribute traffic proportionally according to these weights, sending more traffic to Server 4 than to Servers 1, 2 and 3. This approach is ideal when dealing with heterogeneous server environments where servers have different capacities.
6. Geographical Algorithms
Geographical algorithms direct requests to servers that are geographically closest to the user.
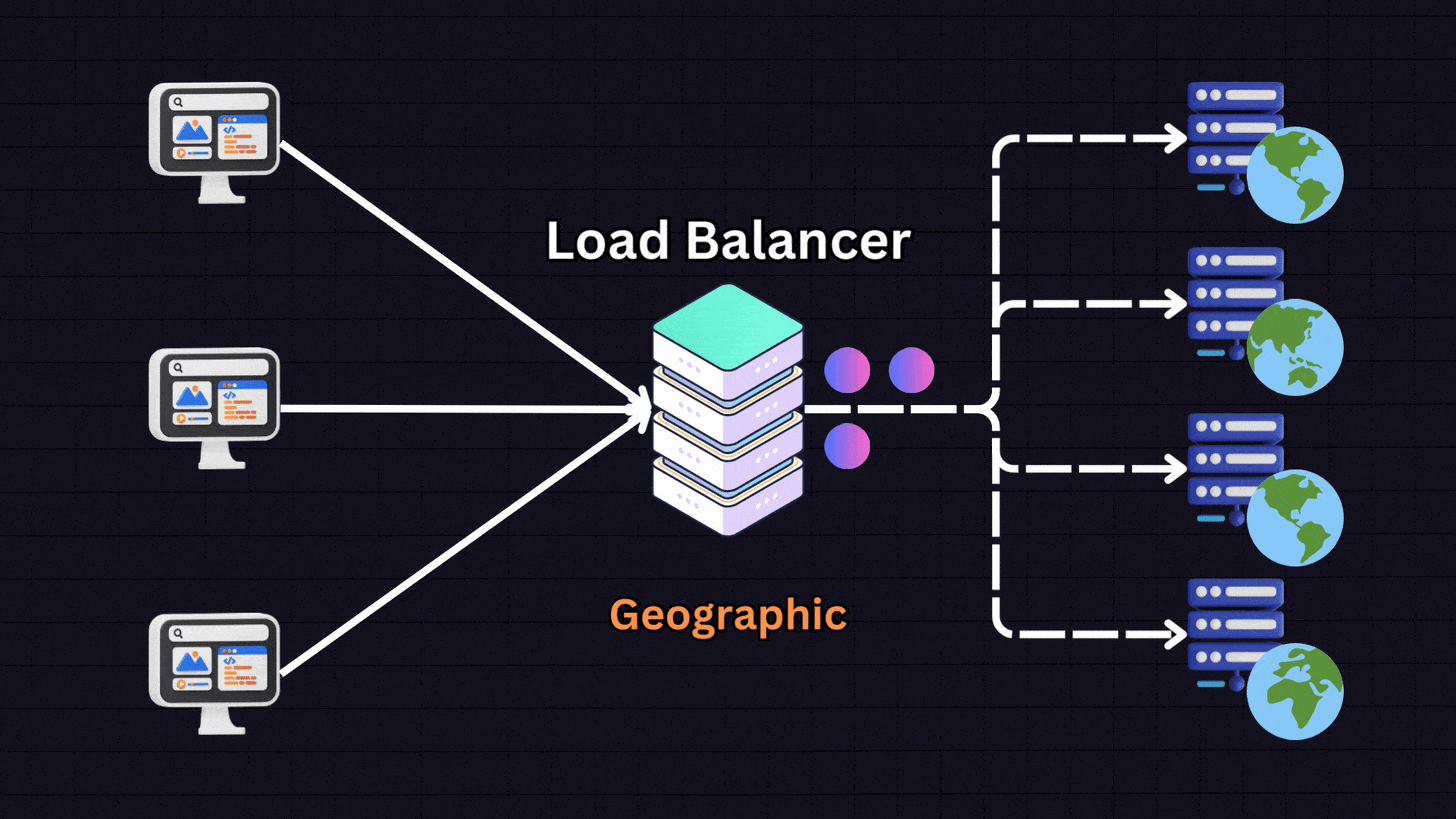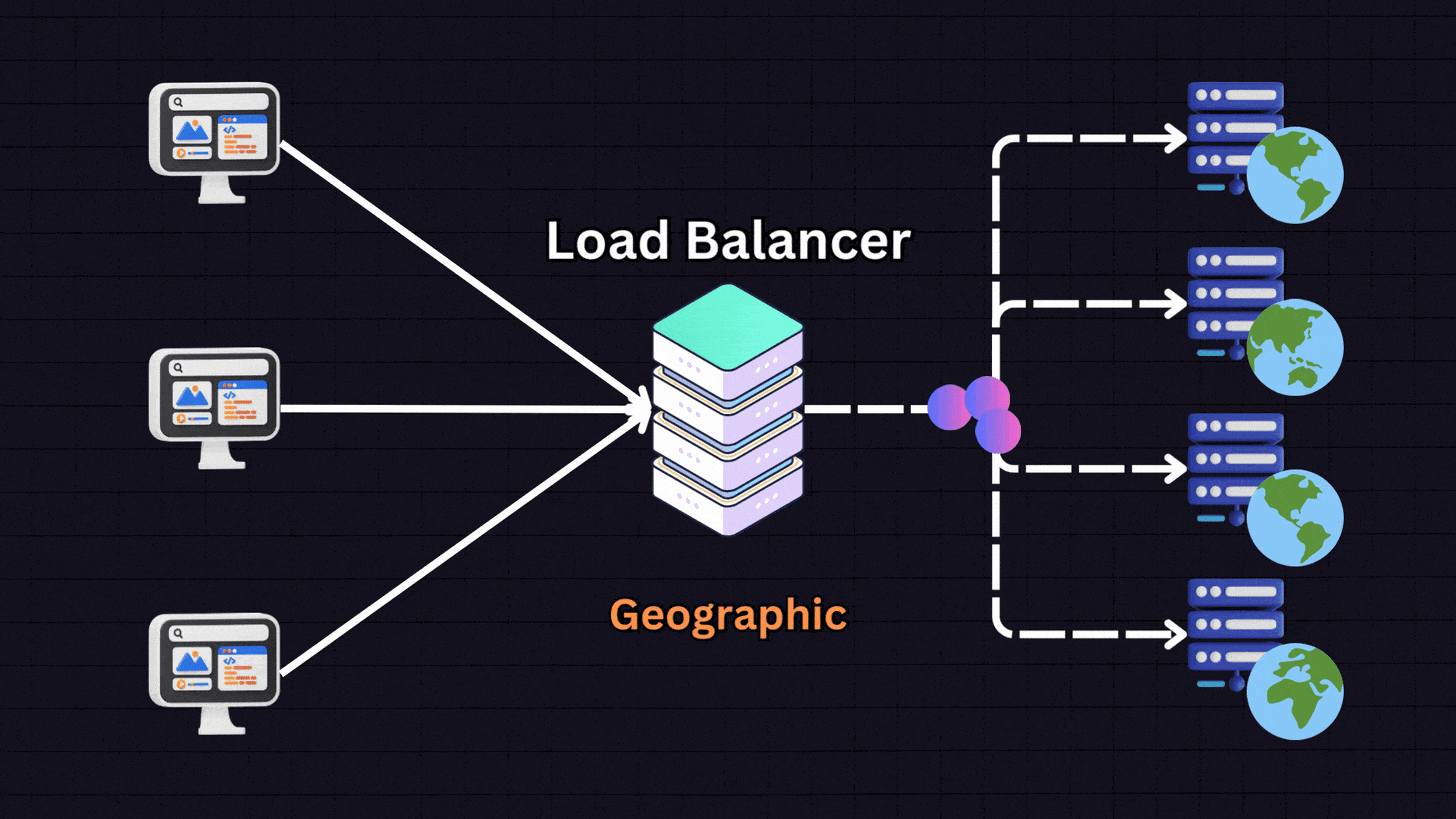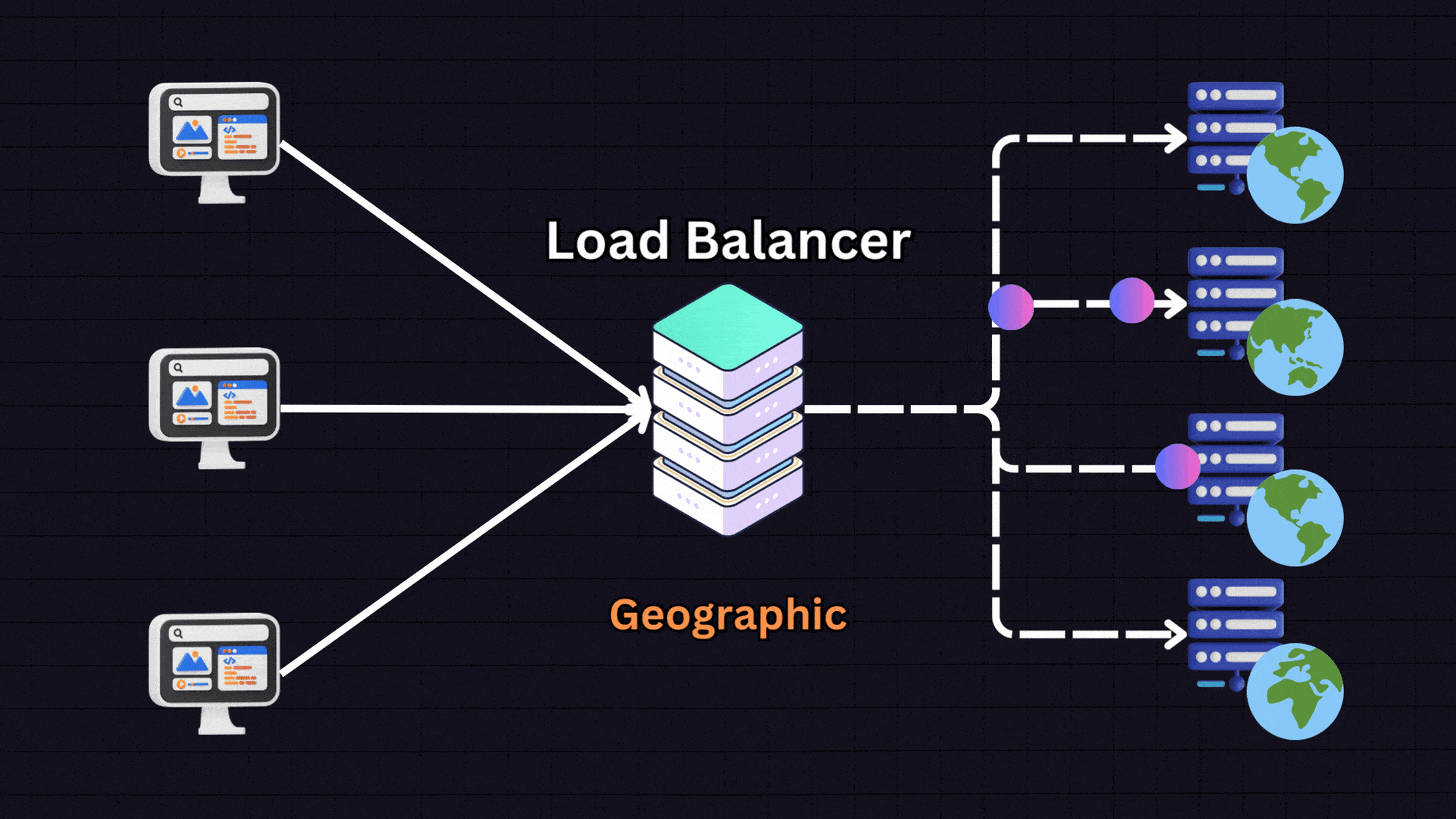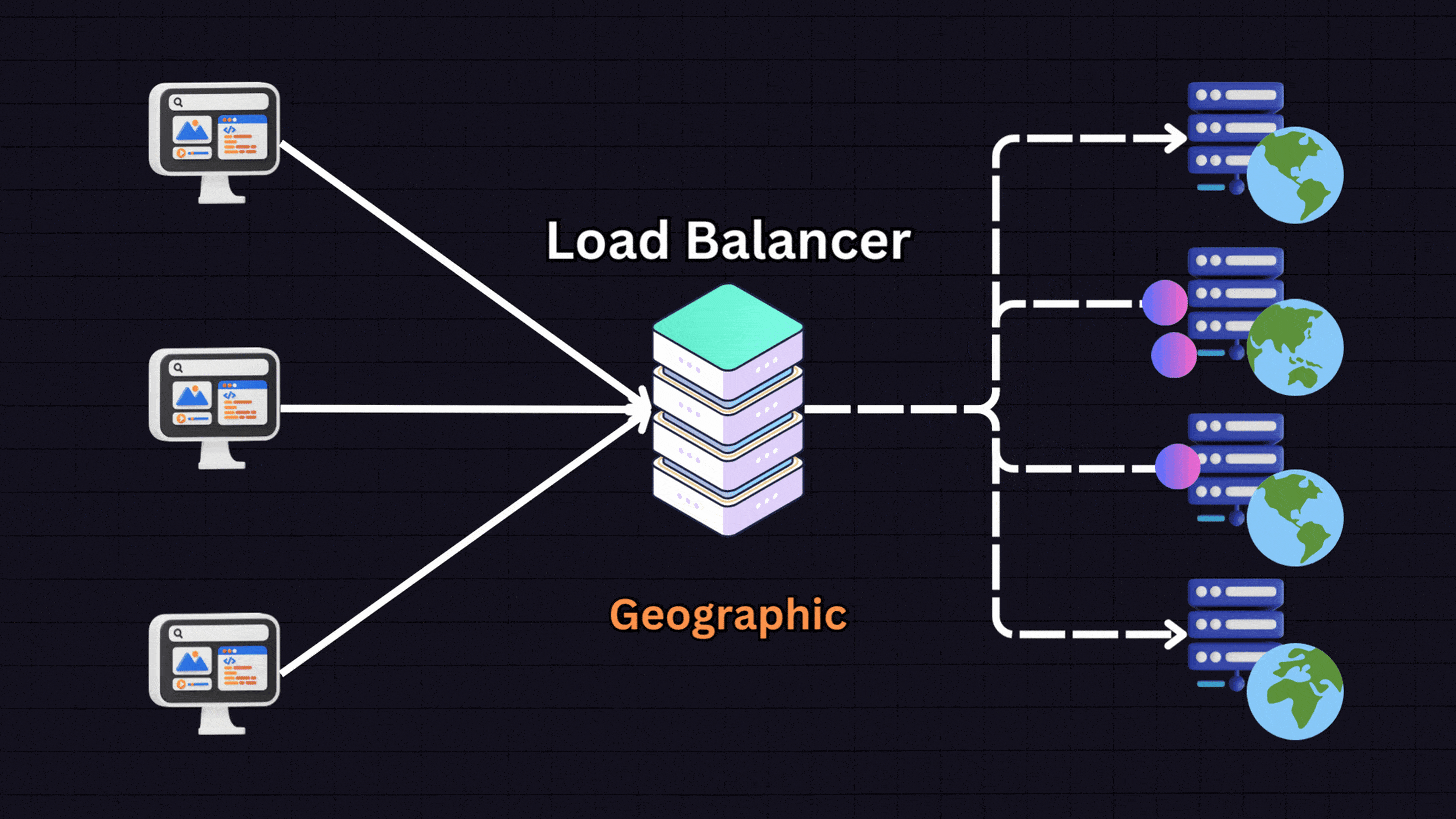
For instance:
A user in Europe → Server located in Europe
A user in US East → Server in US East
A user in US West → Server in US West
The load balancer determines the user’s location based on their IP address and routes them to the nearest server. This approach is useful for global services where reducing latency is important.
7. Consistent Hashing
Consistent hashing uses a hash function to distribute data across various nodes. It works by:
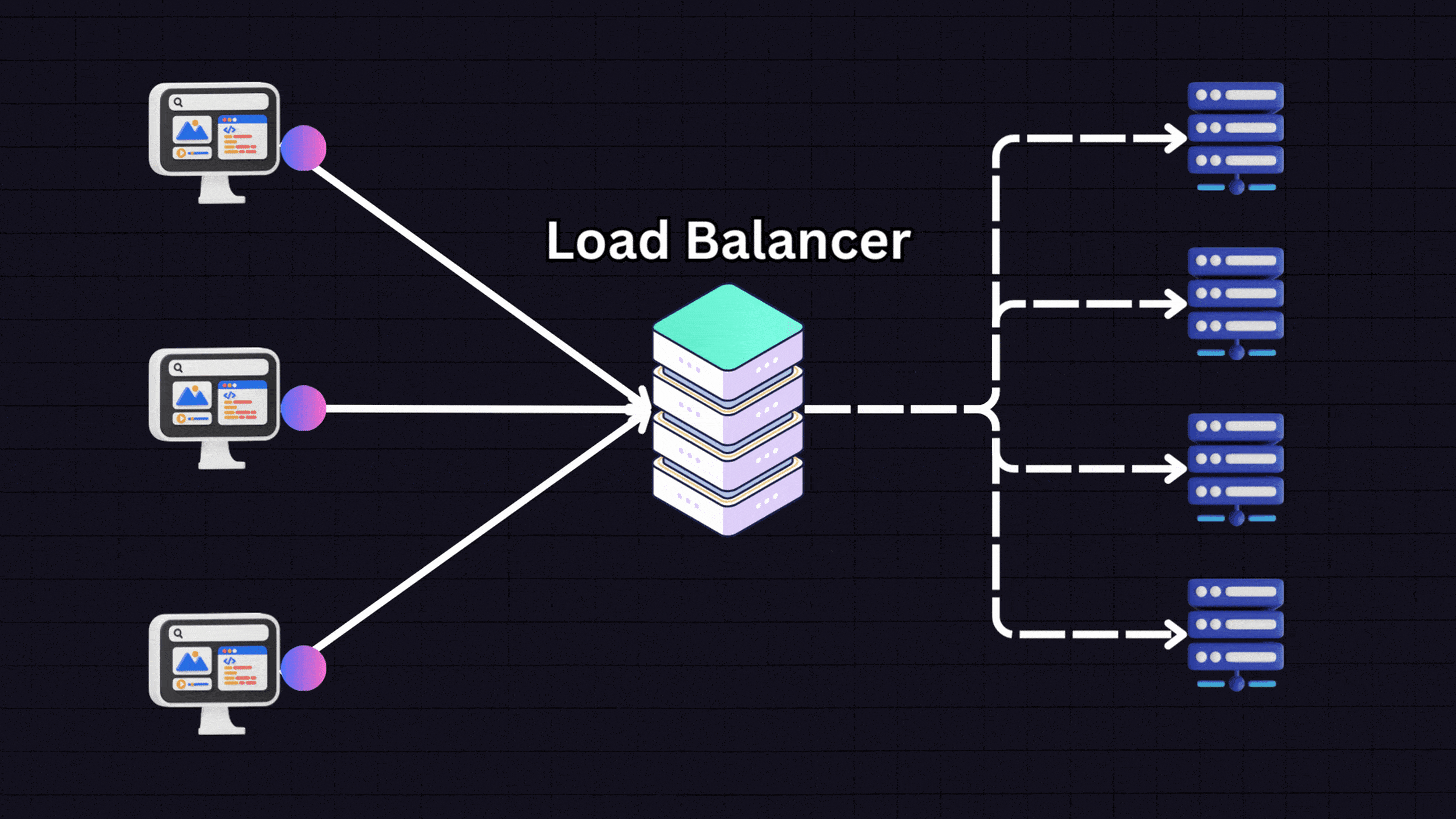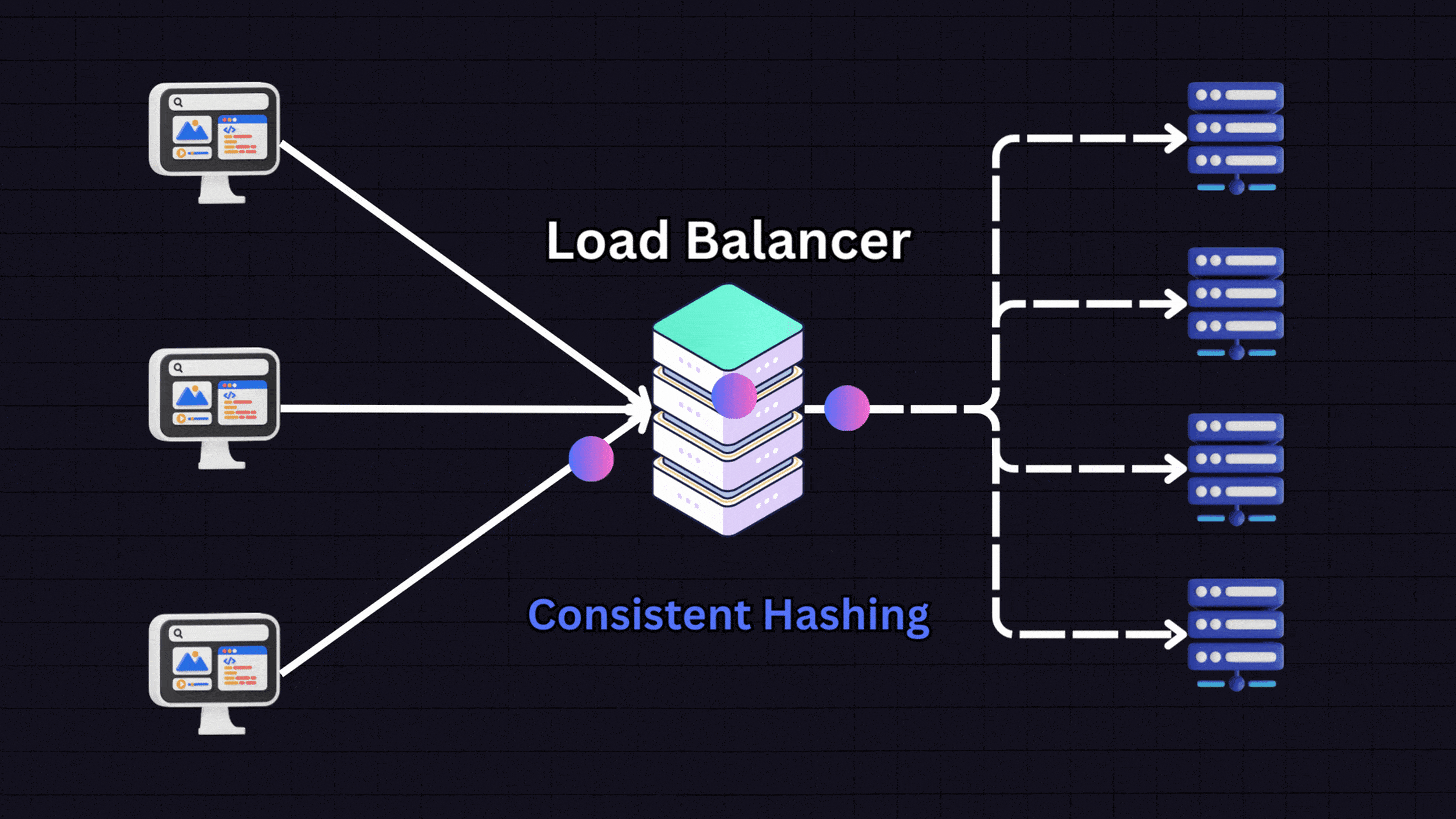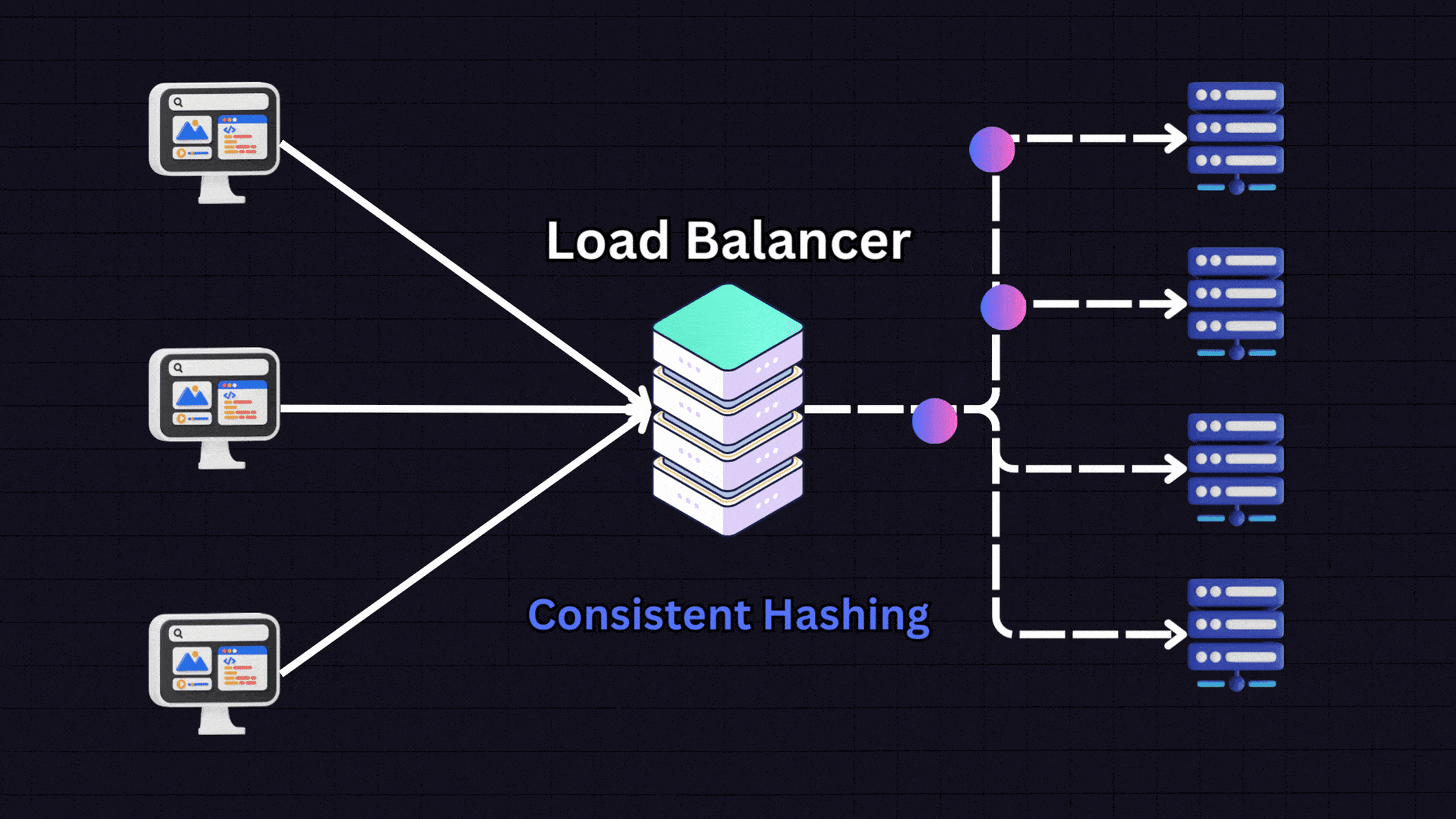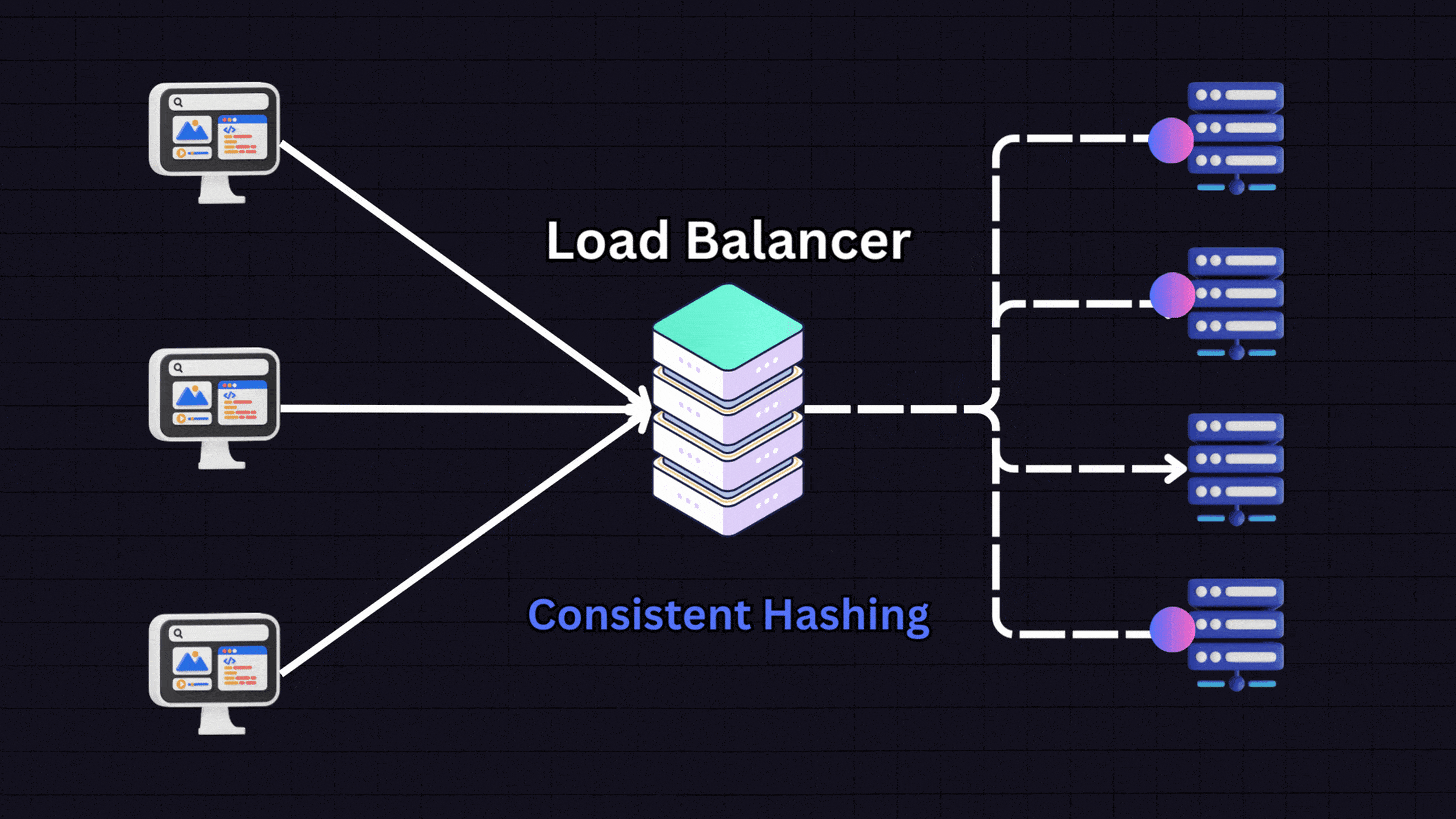
Creating a hash space that forms a circle (the “hash ring”)
Placing servers at different points on this ring
When a request comes in, the load balancer hashes the client’s IP address
The request is directed to the nearest server on the ring
This method ensures the same client consistently connects to the same server (similar to IP hashing) but has additional benefits when adding or removing servers from the pool.
Conclusion
Each load-balancing strategy has its strengths and ideal use cases. The choice depends on your specific infrastructure, application requirements, and user distribution.
If you found this explanation helpful and want to deepen your understanding of load balancing and other system design topics, check out my mentorship program, which includes a System Design Practical Course.
In this hands-on course, you’ll learn how to apply these concepts in real-world scenarios and build systems that can scale to millions of users.
Very helpful!! 🙌🏻