
NoSQL Databases Explained: All Types & When to Use Them
A comprehensive breakdown of NoSQL databases, including all the main types and comparing NoSQL to SQL.


What is a NoSQL Database?
NoSQL (often referred to as “not only SQL” or “non-relational”) databases store data differently than traditional relational databases. They use different data models, including documents, key-value pairs, wide-column stores, and graphs.
This flexibility makes them a good fit for large and unstructured datasets or situations where data structures evolve rapidly.
One of the core differences between NoSQL and relational databases is that they do not have relations the same way SQL databases do, so we cannot do complex joins and queries as in SQL.
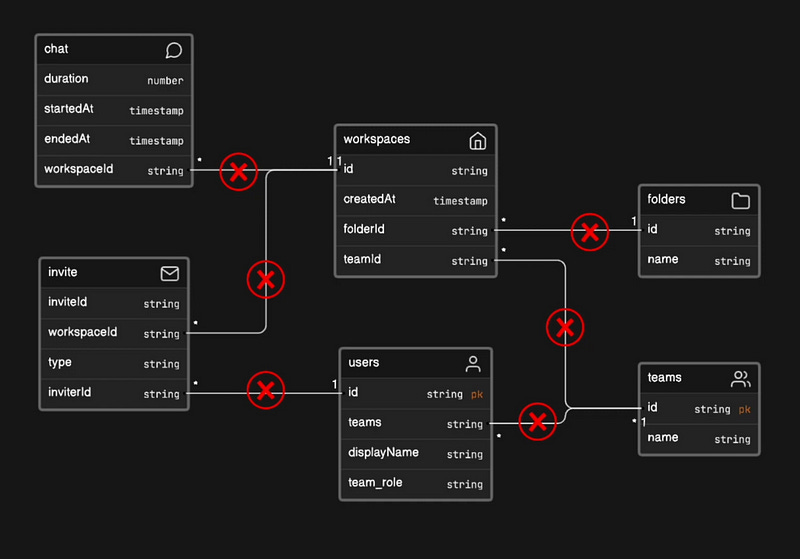
If you need to combine data from different sources, you may need to handle that within your application code.
Benefits of NoSQL
Flexible Schema
NoSQL databases often have a schema-less design, which allows us to store data without predefined structures. This is useful for data that has a complex or ever-changing structure.
Horizontal Scaling
The biggest limitation that NoSQL databases solve is the Scale. NoSQL databases excel at horizontal scaling. By distributing data across multiple servers, you can handle massive datasets and high traffic loads. This can be very important for web applications that experience spikes in usage.
Faster Reads and Writes
If your data doesn’t have many complex relationships and you’re primarily storing and retrieving individual units of information, NoSQL databases (especially key-value stores and document databases) can be faster due to less complex querying.
Development Agility
The flexible schema and focus on specific data models can streamline development for certain applications.
Types of NoSQL Databases
Key-Value Stores
In key-value stores, data is stored as simple key-value pairs. Like giant hash tables or dictionaries, they store data as pairs of unique keys and associated values. The value here can be simple strings, complex data structures, or even blobs of data.
The biggest advantage of key-value stores is their simplicity and speed. Since they primarily reside in RAM, making lookups is extremely fast.
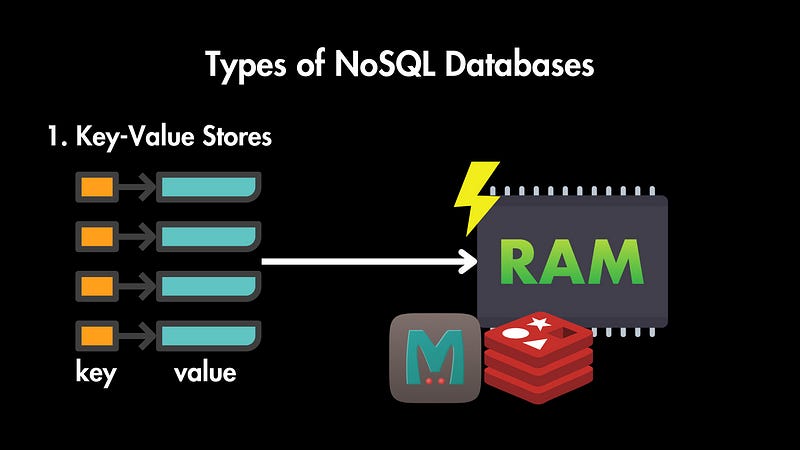
Key-value store examples are Redis, Memcached, etc. We use Redis, for example, when we want to temporarily store frequently accessed data to speed up websites and applications. It works very well for caching or session data.
Document Stores
In document stores, the data is stored as JSON-like documents, which allows us to have complex data structures within a single record.
MongoDB is the most popular example of a document store and the most popular NoSQL database overall. It internally stores data as BSON (Binary JSON), which is faster than JSON itself when it comes to querying the data.
Document stores also have some type of primary key that helps us identify each document.

But there’s no schema or rigid table structure, and fields can vary from document to document. Related data is often stored together within the document, which improves the read performance for common queries.
Some other document store examples are AWS DocumentDB, Firestore, CouchDB, etc.
Wide-Column Stores
In wide-column stores, data is stored in tables, rows, and dynamic columns. Columns can be grouped into column families and unlike relational tables, columns can be added on the fly, which is good for data with evolving schemas.
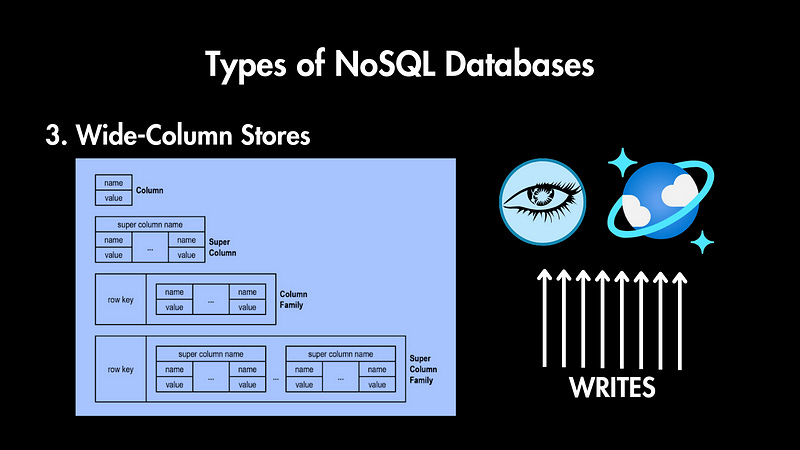
Wide-column database examples are Apache Cassandra or Azure’s CosmosDB. These databases can handle massive scales and are very good for many Write operations. They are specifically Designed to be distributed across hundreds or thousands of nodes.
So wide-column databases are great for — storing huge amounts of data, scaling easily across many machines, and handling lots of writes.
Graph Databases
Graph databases focus on storing entities (nodes) and their relationships (edges), forming graph structures. Both nodes and edges can have properties.
Some examples are Neo4j, Amazon Neptune, and Dgraph.
For example, Amazon uses the Amazon Neptune graph database service to make product recommendations. You probably have seen “Customers who bought this also bought…”, and this is utilizing the graph database to identify which products you might be interested in.
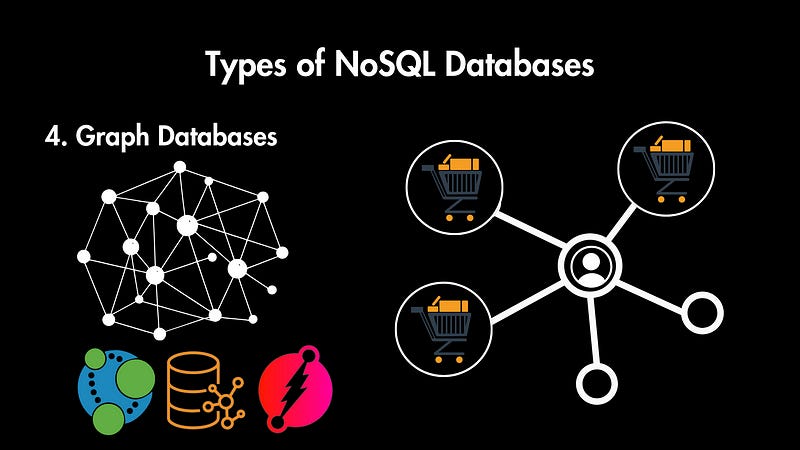
Meta primarily relies on a graph database called TAO (The Associations and Objects), which is internally developed to Represent and analyze connections between people on Instagram and Facebook.
So, graph databases are effective for storing and querying complex relationships and path-based patterns in data.
Scalability
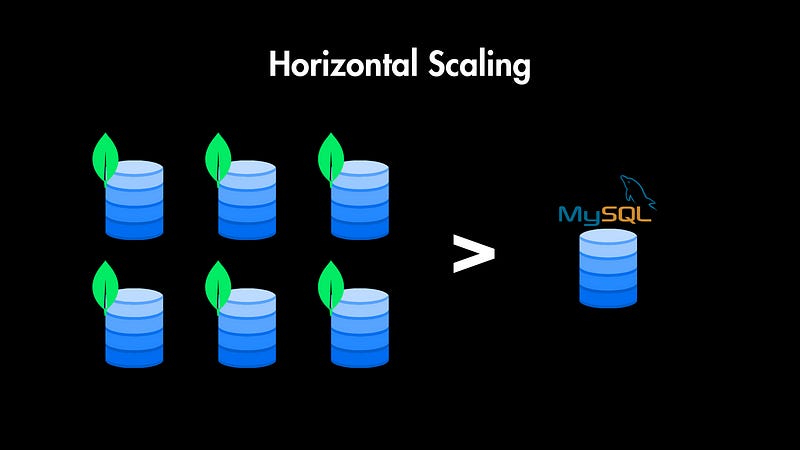
Horizontal Scaling
NoSQL databases are designed to scale horizontally. This means you can add more commodity servers to a cluster, easily increasing storage space and processing power. This is much simpler than trying to scale an SQL database.
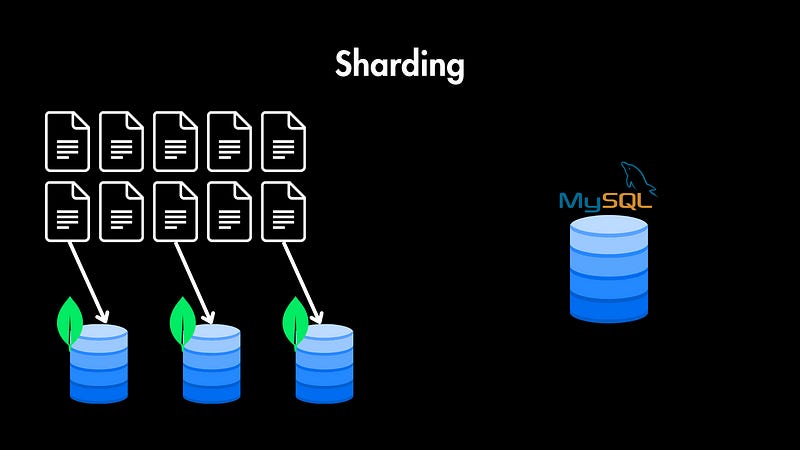
Sharding
Many NoSQL databases support sharding out of the box. Sharding is the process of distributing data across multiple nodes. This lets you avoid the limitations of a single machine and tackle massive datasets.
Traditional relational databases tend to scale vertically. This means you add more RAM, CPU, and faster storage to a single, more powerful machine. There are limits to how much you can scale a single system.
While horizontal scaling in SQL databases is possible, it’s complex:
Sharding
Manually splitting data across multiple machines is a complex task for relational databases. It can also complicate joins — what if you’re trying to do joins and some of the data is in another shard? There are lots of edge cases to consider when sharding relational databases.
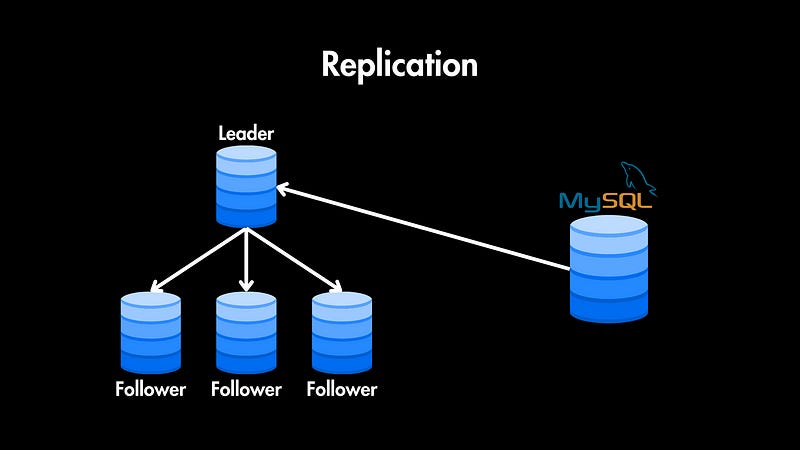
Replication
You can also replicate SQL databases, but primarily for read scaling and fault tolerance, it often doesn’t address write scalability in the same way as NoSQL’s sharding.
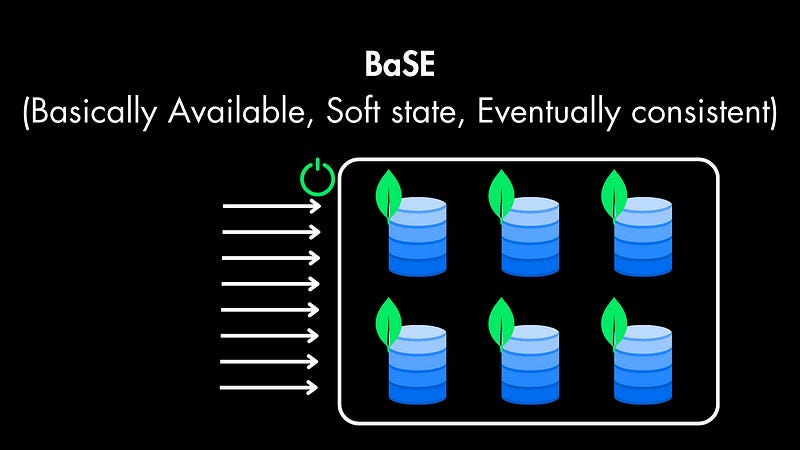
Relaxed Consistency (BaSE)
Non-relational databases drop the ACID properties, but they have their own model, which is called “BaSE” model (Basically Available, Soft state, Eventually consistent). What This means is:
Availability Over Strict Consistency
NoSQL prioritizes keeping the system available for reads and writes even during network partitions or node failures.
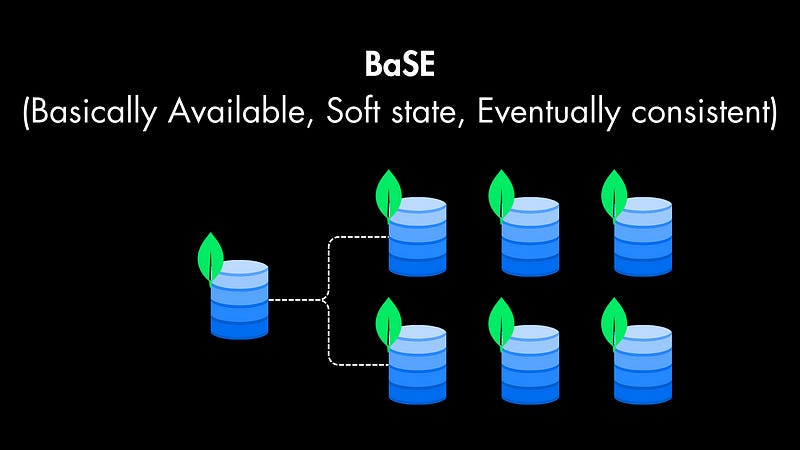
Eventual Consistency
Data changes might not be instantly reflected across all replicas, but the system will eventually converge to a consistent state. This tradeoff allows for greater scalability.
Summary: Choosing Between NoSQL and Relational Databases
NoSQL databases have lots of advantages over SQL databases, but relational databases are still great for:
ACID: SQL databases strictly adhere to ACID (Atomicity, Consistency, Isolation, Durability) principles, guaranteeing that transactions are reliable and data remains consistent even in the case of failures.
Joins: SQL’s strength lies in its ability to perform complex joins across multiple tables, making it an excellent choice for data analysis and reporting where relationships between data are crucial.
Schemas: SQL databases enforce a rigid schema, ensuring data conforms to a specific structure. This improves data integrity and makes it easier to maintain consistency as applications grow.
Structured Data: If your data has a well-defined structure and requires complex joins between tables, a relational database might be better.
Data Integrity: Relational databases enforce data integrity through features like normalization and referential constraints. This might be critical for some financial or accounting applications.
SQL databases are still the go-to for banking systems, financial reporting systems, and multi-step transactions because they ensure reliable transactions and prevent data corruption.
If you’d like to learn more about SQL databases, I recommend you check out this SQL tutorial for Beginners and then SQL Transactions and ACID Properties.
🚀 Join my Free Web Developers Community and Get Access to More Courses.