
System Design Interview: Design Twitter (X)
Learn how to design social media platforms like Twitter and how to handle billions of tweets, followers, and massive data.


In this system design interview scenario, we’ll break down the design of a Twitter-like app, covering everything from the initial requirements to the high-level architecture.
We’ll start by clarifying the functional and non-functional requirements and laying the foundation for our design. Then, we’ll sketch out a high-level API Design, followed by a high-level System Design.
Background
Let’s start with a background of Twitter (now X).
People can follow others, which can be mutual, meaning other users can follow them back.
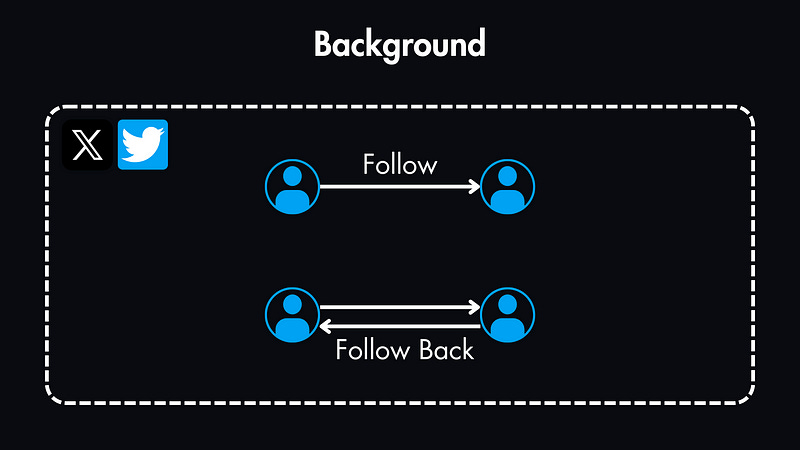
But naturally, some users will end up with more followers than others.
This indicates that it will be a read-heavy system, as most users only browse tweets, while a smaller percentage will actively create tweets.

A typical tweet can contain up to 280 characters of text and may also include images or videos.
Each tweet has interactions at the bottom, allowing users to like, comment, retweet, and follow other users.

Functional Requirements
Let’s prioritize these features. Our must-have features for this system are:
Following: Users need to be able to follow other users.
Tweeting: Users need to create tweets. Tweets can include text (up to 280 characters for most users), images, and videos. (We won’t conver the premium feature of extended tweet length in this basic design).
News Feed: Users need to see tweets from the users they follow. We’ll focus on this type of feed in our design, although it’s worth noting that platforms like X now also offer an algorithmic “For You” feed.

Non-Functional requirements
Now, let’s consider the scale and performance demands that this system needs to handle.
Scale
Research shows that X currently has 500 million Monthly Active Users (MAU). Let’s assume that of these 500M MAU, 200 million are Daily Active Users (DAU).
The average user typically follows around 100 accounts. On average, each user creates 10 daily tweets and reads 100 tweets.

With this information, we can calculate the read and write volumes.
Read Volume: With our assumption, each DAU reads an average of 100 tweets per day. That’s around 200M * 100 = 20 billion reads daily.
Write Volume: If each DAU creates an average of 10 tweets per day, that’s 200M * 10 = 2 billion new tweets daily.

Data Size
Each tweet size can be 1KB on average if it’s text-only. If it contains attachments like images and videos, it can range from 1MB to 5MB.
To simplify, let’s assume an average tweet size of 1MB, even though some tweets with media could be larger.
This means that we’re dealing with 200M * 1MB = 20 petabytes of data read daily.

Key Takeaways
This is clearly a read-heavy system. Meaning we should optimize for efficient reads.
The data storage requirements are huge, so we’ll need to consider scalable storage solutions.
Handling the load of popular users with millions of followers presents a unique challenge.

This sets the stage for the API design and high-level system design sections, where we’ll start tackling these challenges.
API Design
We’ll assume all requests are authenticated with an auth service before reaching our API, and we have a userId in each request.
Because in system design interviews, the interviewer usually assumes you know how authentication works, so it's not the best use of your time to discuss that in detail.

Here are our core endpoints:
1. Create Tweet — POST /tweets
Request parameters:
content(string): The text content of the tweet.mediaIds(array of strings, optional): An array of media IDs (for images, videos, etc.).(Server-side)
userId(string): Obtained from the authentication service.(Server-side)
createdAt(timestamp): Set by the server at the time of creation.
Response payload:
tweetId(string): The ID of the created tweet.createdAt(timestamp): The timestamp when the tweet was created.success(boolean): Indicates whether the tweet was created successfully.

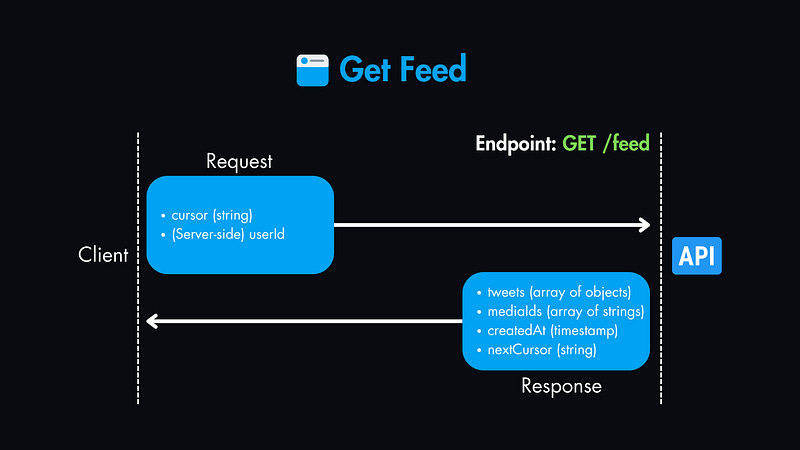
2. Get Feed — GET /feed
Request parameters:
cursor(string, optional): A pagination token to fetch the next set of tweets.(Server-side)
userId(string): Obtained from the authentication service.
Response payload:
tweets(array of objects): An array of tweet objects, each containing:
-mediaIds(array of strings, optional): An array of media IDs
-createdAt(timestamp): Creation timestamp.nextCursor(string, optional): A pagination token to fetch the next set of tweets.
3. Follow — POST /follow/:userId
Request parameters: userId of the user we want to follow.
Response payload: success (boolean): Indicates whether the follow operation was successful.

4. Unfollow — DELETE follow/:userId
Request parameters: userId of the user we want to unfollow.
Response payload: success (boolean): Indicates whether the unfollow operation was successful.

Quick Note: If you’re enjoying this so far, I have a Free System Design Course where you can learn more about each component discussed here.
High-Level Design
Let’s visualize the major components of this system:
Client/Mobile App: This is where users will interact with the system by creating tweets, viewing feeds, and following/unfollowing others — it’s either the frontend browser app or the app on user’s phones.
Load Balancer: All requests will go through our load balancer, which distributes them across multiple app servers. This is especially important for handling the read-heavy traffic of our news feed.
For now, we can use layer 4 (transport layer) load balancing, which operates based on TCP port numbers and IP addresses.
This is suitable for distributing general traffic without needing to inspect the content of the requests. However, we’ll soon change this layer in the scaling section.

API Servers: These servers handle the API requests outlined above, like fetching tweets, filtering feeds, interacting with the database and cache, and rendering responses back to the client.

Database (SQL): While NoSQL databases will be great here at handling large amounts of unstructured data, a relational database (SQL) is better suited for our use case due to the need for complex relationships and joins between users and tweets. We’ll use a relational database (like MySQL or PostgreSQL) to store structured data.
Database Schema
Below is a basic outline of our database schema.
We will have a followers table that stores the IDs of the follower and the followee. These IDs are foreign keys linked to the users table.

The users table will be linked with the tweets table with user IDs. There might also be some small tables, such as likes table, which store the relationship between the tweets and their owners.
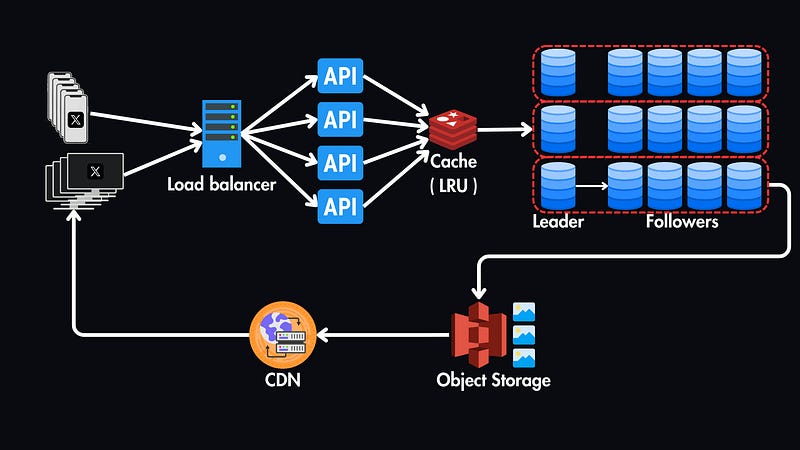
Caching
Back to our high-level design, we will use a cache layer (e.g., Redis or Memcached) in front of the database to store frequently accessed data like popular tweets, user profiles, and follow relationships.
This significantly reduces the load on the database and improves read latency. An LRU (Least Recently Used) cache will be suitable here — a common cache eviction policy to keep the most relevant data in the cache.

Object Storage & CDN
In order to store the media files (such as images and videos) that can be attached to the tweets, we will use an object storage service like AWS S3.
And our SQL database will store the metadata for these media files, such as file names and URLs.
To further reduce the latency of our system, we can implement a CDN (Content Delivery Network) to cache these media files closer to users based on their geographical location.

Specifically, we will use a pull-based CDN, which retrieves content from the origin (object storage) upon the first request and then caches it for subsequent requests.
Scaling the Database
The database will be the primary bottleneck in our current system, so let’s explore replication and sharding strategies to scale our system.
Scaling Reads
We can introduce read replicas of our primary database to scale the reads.
We will have one Master Replica for writing and multiple Read Replicas, which are exact copies of the master database used exclusively for read operations.
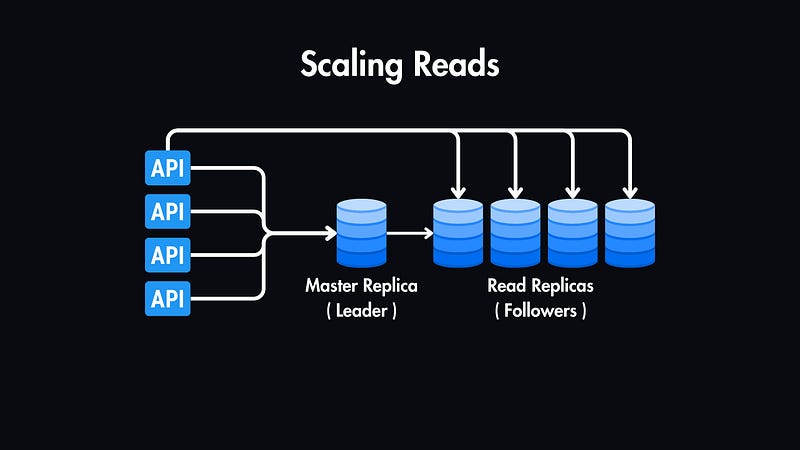
This significantly improves read performance by distributing the load across multiple servers.
In addition to read replicas, we’ll leverage our cache layer to further to store popular tweets, user profiles, and follow relationships, which will reduce the need to query the database for frequently accessed data.

Scaling Writes
However, there will also be moments of peak traffic, and our current single Master replica is a single point of failure.
To scale writes, we can shard the tweets table based on the user_id. This means we'll horizontally partition the table across multiple database servers (shards). Each shard will store the tweets for a specific range of user IDs.

We’ll use a technique like consistent hashing to map user IDs to shards, to ensure even distribution of data, and to minimize the impact of adding or removing shards.
Separate Read/Write APIs
We can separate our APIs read and write operations to further optimize performance.
The load balancer can direct read requests to read APIs and write requests to write APIs.

To achieve this, we need to use layer 7 (application layer) load balancing which allows us to make routing decisions based on the content of the request itself, such as the HTTP method (GET vs. POST) or the URL path.
This is perfect for our scenario because we can direct all the GET requests to the read APIs and all the other requests to our write APIs.
Handling Peak Load: Message Queues and Fan-Out
To manage peak traffic and ensure a smooth user experience, we can introduce a message queue system. This works as follows:

1. Publish: When a user creates a tweet, the API server publishes a message to the message queue.
2. Fan-out: This message is then fanned out to multiple worker nodes (a cluster) that handle the following tasks concurrently:
Database Write: The tweet is written to the appropriate database shard.
Temporary Cache Update: A copy of the tweet is added to a temporary cache specifically for new tweets.
Fan-out to Follower Feeds: The tweet is pushed to the individual news feeds of the tweet creator’s followers.
3. Read from Cache: While the tweet is being written to the database, other users can already see it in their feeds by reading from the temporary cache.
4. Cache Update (Main): Once the tweet is written to the database, it’s also added to the main cache (LRU) for long-term storage and is removed from the temporary cache.
Wrap-up
Here’s the final overview of our high-level design.

We covered a lot and this overview gives you a solid foundation, but this is just scratching the surface.
Real-world systems like Twitter are incredibly complex, with challenges like concurrent updates, tweet ordering, pagination, and more.
If you’d like to learn more, you can read the official design docs by the Twitter team.
Check out the animated video version of this article here 👇